Klasifikace je přístup strojového učení pod dohledem, při kterém se algoritmus učí ze vstupních dat, která mu byla poskytnuta – a poté toto učení využívá ke klasifikaci nových pozorování.
Jinými slovy, trénovací soubor dat se používá k získání lepších okrajových podmínek, které lze použít k určení každé cílové třídy; jakmile jsou tyto okrajové podmínky určeny, je dalším úkolem předpovědět cílovou třídu.
Binární klasifikátory pracují pouze se dvěma třídami nebo možnými výsledky (příklad: pozitivní nebo negativní sentiment; zda věřitel zaplatí půjčku nebo ne; atd.) a klasifikátory více tříd pracují s více třídami (příklad: ke které zemi patří vlajka, zda je na obrázku jablko nebo banán nebo pomeranč; atd.) Multiclass předpokládá, že každému vzorku je přiřazena jedna a pouze jedna značka.

Jedním z prvních populárních algoritmů pro klasifikaci ve strojovém učení byl Naive Bayes, pravděpodobnostní klasifikátor inspirovaný Bayesovým teorémem (který nám umožňuje provádět odůvodněné dedukce událostí, které se dějí v reálném světě, na základě předchozích znalostí pozorování, které to mohou naznačovat). Název („naivní“) je odvozen od skutečnosti, že algoritmus předpokládá, že atributy jsou podmíněně nezávislé.
Algoritmus je jednoduchý na implementaci a obvykle představuje rozumnou metodu pro zahájení klasifikačního úsilí. Lze jej snadno škálovat na větší soubory dat (trvá lineární čas oproti iterační aproximaci, která se používá u mnoha jiných typů klasifikátorů a je dražší z hlediska výpočetních zdrojů) a vyžaduje malé množství trénovacích dat.
Naivní Bayes však může trpět problémem známým jako „problém nulové pravděpodobnosti“, kdy je podmíněná pravděpodobnost pro určitý atribut nulová, což neposkytuje platnou předpověď. Jedním z řešení je využití vyhlazovacího postupu (např.: Laplaceova metoda).

P(c|x) je posteriorní pravděpodobnost třídy (c, cíl) daná prediktorem (x, atributy). P(c) je priorní pravděpodobnost třídy. P(x|c) je pravděpodobnost, což je pravděpodobnost prediktoru vzhledem ke třídě, a P(x) je priorita pravděpodobnosti prediktoru.
První krok algoritmu spočívá ve výpočtu prioritní pravděpodobnosti pro dané štítky tříd. Poté zjištění pravděpodobnosti s každým atributem, pro každou třídu. Následně dosazením těchto hodnot do Bayesova vzorce &vypočítáme posteriorní pravděpodobnost a poté zjistíme, která třída má vyšší pravděpodobnost vzhledem k tomu, že vstup patří do třídy s vyšší pravděpodobností.
Je poměrně jednoduché implementovat Naive Bayes v jazyce Python s využitím knihovny scikit-learn. V rámci knihovny scikit-learn existují vlastně tři typy Naive Bayesova modelu: (a) Gaussovský typ (předpokládá, že rysy se řídí normálním rozdělením podobným zvonu), (b) Multinomický (používá se pro diskrétní počty, ve smyslu množství případů, kdy je výsledek pozorován v x pokusech) a (c] Bernoulliho (užitečný pro binární vektory rysů; oblíbeným případem použití je klasifikace textu).
Dalším populárním mechanismem je rozhodovací strom. Při zadání dat atributů spolu s jejich třídami strom vytváří posloupnost pravidel, která lze použít ke klasifikaci dat. Algoritmus rozdělí vzorek na dvě nebo více homogenních množin (listů) na základě nejvýznamnějších diferenciátorů ve vašich vstupních proměnných. Pro výběr diferenciátoru (prediktoru) algoritmus zváží všechny rysy a provede na nich binární rozdělení (pro kategoriální data rozdělí podle kategorie; pro spojitá zvolí mezní hodnotu). Poté vybere ten s nejmenšími náklady (tj. nejvyšší přesností) a rekurzivně opakuje, dokud úspěšně nerozdělí data ve všech listech (nebo nedosáhne maximální hloubky).
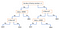
Rozhodovací stromy jsou obecně jednoduché na pochopení a vizualizaci a nevyžadují velkou přípravu dat. Tato metoda si také poradí s číselnými i kategoriálními daty. Na druhou stranu se složité stromy špatně zobecňují („overfitting“) a rozhodovací stromy mohou být poněkud nestabilní, protože malé odchylky v datech mohou vést k vytvoření zcela jiného stromu.
Metodou pro klasifikaci, která je odvozena od rozhodovacích stromů, je Random Forest, v podstatě „meta-estimátor“, který fituje řadu rozhodovacích stromů na různých dílčích vzorcích souborů dat a pomocí průměru zlepšuje predikční přesnost modelu a kontroluje over-fitting. Velikost dílčích vzorků je stejná jako velikost původního vstupního vzorku – vzorky jsou však vybírány s nahrazením.
Náhodné lesy mají tendenci vykazovat vyšší míru odolnosti vůči přetypování (>odolnost vůči šumu v datech) a efektivní dobu provádění i u větších souborů dat. Jsou však citlivější k nevyváženým souborům dat, jsou také o něco složitější na interpretaci a vyžadují více výpočetních prostředků.
Dalším oblíbeným klasifikátorem v ML je logistická regrese – kde se pravděpodobnosti popisující možné výsledky jednoho pokusu modelují pomocí logistické funkce (klasifikační metoda navzdory názvu):

Tady vypadá logistická rovnice:
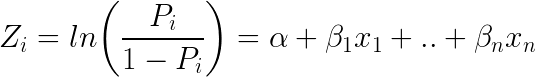
Při dosazení e (exponentu) na obě strany rovnice dostaneme:
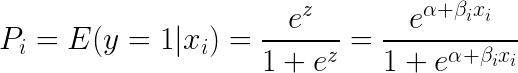
Logistická regrese je nejužitečnější pro pochopení vlivu několika nezávislých proměnných na jednu výslednou proměnnou. Je zaměřena na binární klasifikaci (pro problémy s více třídami používáme rozšíření logistické regrese, jako je multinomická a ordinální logistická regrese). Logistická regrese je oblíbená napříč případy použití, jako je analýza úvěrů a sklon k odpovědi/koupi.
V neposlední řadě se pro klasifikační problémy často používá také kNN (pro „k Nearest Neighbors“). kNN je jednoduchý algoritmus, který ukládá všechny dostupné případy a klasifikuje nové případy na základě míry podobnosti (např. funkce vzdálenosti). Ve statistických odhadech a rozpoznávání vzorů se používá již od počátku 70. let 20. století jako neparametrická technika:


.