Den måde, vi tænker på i en moderne, postindustrialiseret verden, er kendetegnet ved stigende konceptuel abstraktion. Den videnskabelige metode har forandret vores verden, og den har forandret den måde, vi tænker om verden på i dagligdagen. Piaget kaldte dette for det formelle operationelle stadium: vi tænker ved at manipulere abstrakte begreber løsrevet fra eksempler fra det virkelige liv. Dette var helt fremmed for vores ikke alt for fjerne forfædre, som det fremgår af eksperimenter i fjerntliggende landsbyer i Sovjetunionen på randen af industrialiseringen.
Abstraktion er overalt: Mens ordet procent optrådte næsten ingen steder for kun 100 år siden, dukker det nu op omkring hvert 5.000. ord i den gennemsnitlige engelske tekst, hvilket udgør 0,02 procent af alle ord.
På en måde er vi tvunget til abstrakt tænkning: Vi lever i en verden, som vores evolutionære forfædre ikke har set, og det er især vores evner til konceptuel tænkning, der forsøger at følge med den hurtighed, hvormed vores omgivelser skifter, og til hvilke digitale, videnbaserede områder de skifter. Men det er ikke en triviel opgave. Vores hjerner er ikke optimeret til at være rationelle og objektive: Wikipedia opregner omkring 200 kognitive bias, psykologiske mønstre, hvor vores opfattelse forvrænger virkeligheden og afholder os fra rationelle vurderinger.
Tallets falske tillid
Verden , som vi møder den , er usikker. Moderne neurovidenskabelige teorier ser vores hjerner som enheder, der konstant forsøger at træffe optimale beslutninger under usikkerhed.
I en tid, hvor en pandemi spreder sig over hele kloden og truer liv, job og det sociale liv, som vi kender det, er usikkerheden overalt.
Afstraheringen af verden fjerner virkelighedens larm og klirren og foregiver en følelse af objektivitet i lyset af usikkerheden. Tal giver et indtryk af uangribelighed, af at give os noget stabilt at holde fast i. De føles betryggende for os, og hvorfor skulle de ikke være det? Tal har været et uhyre nyttigt redskab til at skabe orden i verden og til at manipulere den med stor succes. De er måske det vigtigste teknologiske fremskridt, som menneskeheden har gjort siden opdagelsen af ilden.
Men tal er ikke altid lig med tal. Tal er forbundet med en iboende risiko: Abstraktion er vanskelig, videnskabelig undersøgelse er vanskelig, og tal kan skjule kampen bag deres tilblivelse, usikkerheden om oprindelsen bag den halo af objektiv sandhed, de udstråler.
Statistikkens vanskeligheder
Statistik vedrører ifølge Wikipedia indsamling, organisering, analyse, fortolkning og præsentation af data.
Tal er en af de centrale måder at repræsentere data på. Og der flyder mange tal rundt i medierne og den offentlige debat i disse dage: dødsrater, samlede antal tilfælde, R0-faktorer, skøn over effektiviteten af modforanstaltninger … men meget ofte lurer der ubesvarede spørgsmål bag dem.
Hvor man antager, hvad data fortæller om virkelighedens objektive tilstand, skal der besvares nogle centrale spørgsmål:
- Hvordan blev dataene indsamlet og organiseret?
- Hvordan præsenteres de?
- Hvordan skal de fortolkes?
Vigtigheden af dataindsamling
Covid-19 er en næsten hidtil uset udfordring for det globale samfund (lad os ikke tale om klimaændringer…) og har fået folk over hele verden til at holde deres kollektive åndedræt inde. Så i dette miljø er det kun naturligt at lede efter tal, der giver os en fornemmelse af sikkerhed om, hvad der virkelig foregår.
Men de foranstaltninger, der er truffet for at bremse spredningen af virussen, er ikke et videnskabeligt eksperiment, og derfor bør vi være meget forsigtige med at behandle det som et sådant. Der er flere punkter, hvor test for virussen afviger væsentligt fra et egentligt eksperiment, og hvor fordomme strømmer ind. Det er meget vigtigt at holde sig for øje, at det rent faktisk er tilfældet, og at tallene er der for at blive nydt med et betydeligt gran salt.
- Hvem bliver testet? Hvis man hovedsageligt tester folk, der rejser ind fra “højrisikoområder” (som Iran, Italien og Kina), opstår der en selektionsgruppebias, hvilket fører til en skæv fordeling, der indikerer, at for de fleste mennesker fra højrisikoområder er blevet smittet, selv om folk fra andre steder også kunne være det, men ikke bliver opdaget.
- Sammenligning af tal mellem lande er af begrænset værdi, fordi antallet af test varierer meget mellem dem. Mens Sydkorea på sit højdepunkt har foretaget omkring 10 000 test om dagen, og Tyskland ikke er langt efter dette tal, tester andre lande meget mindre og opdager derfor et meget mindre antal infektioner.
- I nogle steder i nogle perioder vokser antallet af patienter med en bekræftet Covid-19-infektion eksponentielt, mens antallet af test stiger eksponentielt, og det samme gør antallet af test. I princippet kan dette føre til en stor vækst i antallet af påvisninger ,selv om antallet af smittede personer forbliver konstant.
- Mange mennesker har næsten ingen symptomer eller kun meget milde symptomer, og derfor vil mange mennesker ikke gå uopdaget hen, især hvis testkapaciteten er overbelastet og derfor er begrænset til en lille gruppe af personer fra udvalgte grupper. Situationen i Washington, hvor viruset blev sporet til at have været til stede flere uger før det første bekræftede tilfælde, understreger dette problem godt.
Så før vi ser på at fortolke dataene (sådan og sådan er dødeligheden, og sådan er antallet af smittede patienter), er vi nødt til at forstå, hvordan dataene er blevet indsamlet.
For et par dage siden dukkede der en widget op på min telefonskærm, hvor antallet af bekræftede tilfælde stod med store røde bogstaver: 201463 mennesker var blevet smittet med coronavirus! I betragtning af at det reelle antal globale tilfælde nemt kan afvige med en faktor 10-50, tror jeg ikke, at det at foregive at tælle dem op til den enkelte person hjælper til at nære en forståelse af vanskeligheden ved dataindsamlingsprocessen.
Den dødelighedsrate kastes ligeledes ofte rundt, men har en næsten lige så stor usikkerhed knyttet til sig. En enorm forvirrende faktor omfatter demografi (op til 70 procent af patienterne i Tyskland er unge mennesker i god form, der vender tilbage fra skirejser i Italien, hvilket inducerer endnu en stor selektionsgruppe bias), mens en stor del af de ramte i Italien er gamle, til dels fordi gamle mennesker i Italien er stærkere integreret i det sociale liv. Og så er der sandsynligvis mange flere uopdagede tilfælde i Italien (tænk på, at 70 tyskere, der vendte tilbage fra ferie i Sydtyrol, blev testet positive på et tidspunkt, hvor der i hele delstaten kun var 2 bekræftede tilfælde). Dette og det forhold, at Tyskland begyndte at teste mere og tidligere, har medført en forskel i dødeligheden på næsten en faktor 50 mellem to på overfladen relativt ens lande.
Dernæst er der tidsforskydninger mellem infektion og helbredelse, der skal tages i betragtning, effektiviteten af intensiv pleje, den rolle, som rygning og luftforurening spiller (høj i Italien og Kina og mere udbredt blandt mænd), landets demografi, hospitalernes kapacitet, spørgsmålet om, hvilke patienter der tælles med som Covid-19-dødsfald (det første tyske dødsfald var en 78-årig kræftpatient i et sent stadie i palliativ pleje, så man kan diskutere, i hvilken grad hans død virkelig skal medregnes i Covid-19) osv.
Det er derfor misvisende at sige “dødsraten er det og det”, “og at bedømme, hvor farligt Covid-19 virkelig er, alene på grundlag af disse tal. Hvis vi taler om en dødelighedsprocent, skal vi være opmærksomme på, hvor den kommer fra, og hvad den reelt siger.
Vedtagelse af en bayesiansk ramme
I bayesiansk statistik udtrykker sandsynligheder vores grad af tro på en begivenhed. Et bayesiansk estimat af en størrelse indeholder altid det, vi tror, vi ved om størrelsen, plus vores estimat af den iboende usikkerhed ved størrelsen.
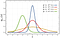
Tal udtrykker vores viden om denne verden: men da denne viden nødvendigvis er probabilistisk, repræsenteres størrelser i bayesiansk statistik i stedet af sandsynlighedsfordelinger (som kan være en klokkekurve som i ovenstående graf) i stedet for enkelte tal. Bredden af fordelingen repræsenterer vores grad af sikkerhed i vores skøn. Det højeste punkt i grafen er vores bedste gæt (middelværdien af gausseren), men hvis fordelingen er meget bred, fortæller vores bedste gæt os ikke ret meget.
Som denne store dybdegående gennemgang af vores mulige foranstaltninger mod det forklarer i detaljer, er der rigtig mange ubekendte, når det drejer sig om Covid-19, og for mange ukendte ubekendte til, at vi kan svinge nogen tal med for stor sikkerhed (det forklarer også, hvorfor stærke foranstaltninger er vores bedste politik lige nu, fordi de køber os tid til at få et klarere billede).

Dette diagram har rejst verden rundt og er fra en artikel, der blev offentliggjort i weekenden af Neil Ferguson et al. ved Imperial College London.
Uafhængigt af, hvor vigtigt budskabet er (det førte til politiske ændringer i USA og Storbritannien), er den måde, hvorpå grafen repræsenterer kurverne, misvisende. Hvad er de implicitte parametre, der blev indsat i simuleringen, og hvor store er deres konfidensintervaller? Virkningerne af vejret/forskellige sociale distancemålinger/social struktur/udbredte behandlinger er alle usikre, og ingen af disse faktorer er blevet bestemt af empiriske undersøgelser, men er endnu kun gisninger.
Som Jeremy Howard siger i sin praktiske sammenfatning af Covid-19-situationen, kan fejlbarrerne omkring disse kurver, selv om de ser forfærdelige ud, være næsten lige så store som selve kurverne.
Trods usikkerheden
Bottom line: Det kan være svært at bevare roen i lyset af usikkerheden, men der er en vis visdom i det.
I politikere bliver det desværre ofte tolket som et tegn på svaghed at erkende usikkerheden. Derfor mener jeg, at det er det videnskabelige samfunds ansvar at understrege, hvilken rolle det spiller i vurderingen af, hvad der sker, hvad det betyder med hensyn til de foranstaltninger, vi bør træffe, og hvorfor denne usikkerhed er en af de bedste grunde til, at vi har brug for mere tid til langsomt at overvinde den gennem en mere stringent, videnskabelig evaluering af virussen og derefter træffe beslutning om den bedste langsigtede strategi.
Vi kan godt lide at have tal at holde fast i, når pandemiens mørke sky truer over vores alle sammens hoveder. Men før der kommer klarere fakta frem, før det globale samfund har et fastere greb om situationen, er det bedre at modstå usikkerheden end at fastholde fakta for at bedrage os selv til komfort eller, i den anden yderlighed, at besætte os selv til en panik, der kommer af at tro, at vi ved bedre, hvad der foregår, end vi i virkeligheden gør.