La classificazione è un approccio di apprendimento automatico supervisionato, in cui l’algoritmo impara dai dati di input forniti – e poi usa questo apprendimento per classificare le nuove osservazioni.
In altre parole, il set di dati di training è impiegato per ottenere migliori condizioni di confine che possono essere usate per determinare ogni classe target; una volta che tali condizioni di confine sono determinate, il prossimo compito è prevedere la classe target.
I classificatori binari lavorano con solo due classi o possibili risultati (esempio: sentimento positivo o negativo; se il prestatore pagherà o meno il prestito; ecc), e i classificatori multiclasse lavorano con più classi (esempio: a quale paese appartiene una bandiera, se un’immagine è una mela o una banana o un’arancia; ecc). Multiclasse presuppone che ogni campione sia assegnato a una e una sola etichetta.

Uno dei primi algoritmi popolari per la classificazione nell’apprendimento automatico è stato Naive Bayes, un classificatore probabilistico ispirato al teorema di Bayes (che ci permette di fare deduzioni ragionate su eventi che accadono nel mondo reale sulla base della conoscenza preliminare di osservazioni che possono implicarlo). Il nome (“Naive”) deriva dal fatto che l’algoritmo assume che gli attributi siano condizionatamente indipendenti.
L’algoritmo è semplice da implementare e di solito rappresenta un metodo ragionevole per iniziare gli sforzi di classificazione. Può facilmente scalare a grandi insiemi di dati (richiede un tempo lineare rispetto all’approssimazione iterativa, utilizzata per molti altri tipi di classificatori, che è più costosa in termini di risorse di calcolo) e richiede una piccola quantità di dati di allenamento.
Tuttavia, Naive Bayes può soffrire di un problema noto come ‘problema della probabilità zero’, quando la probabilità condizionata è zero per un particolare attributo, non riuscendo a fornire una previsione valida. Una soluzione è quella di sfruttare una procedura di smoothing (es: metodo Laplace).

P(c|x) è la probabilità posteriore della classe (c, target) dato il predittore (x, attributi). P(c) è la probabilità anteriore della classe. P(x|c) è la probabilità che è la probabilità del predittore data la classe, e P(x) è la probabilità anteriore del predittore.
Il primo passo dell’algoritmo consiste nel calcolare la probabilità anteriore per le etichette di classe date. Poi trovare la probabilità di probabilità con ogni attributo, per ogni classe. Successivamente, mettendo questi valori nella formula di Bayes &calcolando la probabilità posteriore, e poi vedere quale classe ha una probabilità più alta, dato che l’input appartiene alla classe a più alta probabilità.
È piuttosto semplice implementare Naive Bayes in Python sfruttando la libreria scikit-learn. Ci sono in realtà tre tipi di modello Naive Bayes sotto la libreria scikit-learn: (a) Tipo gaussiano (assume che le caratteristiche seguano una campana, distribuzione normale), (b) Multinomiale (usato per i conteggi discreti, in termini di quantità di volte che un risultato è osservato attraverso x prove), e (c) Bernoulli (utile per vettori di caratteristiche binarie; un caso d’uso popolare è la classificazione del testo).
Un altro meccanismo popolare è l’albero delle decisioni. Dato un dato di attributi insieme alle sue classi, l’albero produce una sequenza di regole che possono essere usate per classificare i dati. L’algoritmo divide il campione in due o più insiemi omogenei (foglie) in base ai differenziatori più significativi nelle vostre variabili di input. Per scegliere un differenziatore (predittore), l’algoritmo considera tutte le caratteristiche e fa una divisione binaria su di esse (per dati categorici, dividere per gatto; per continui, scegliere una soglia di cut-off). Sceglierà poi quella con il minor costo (cioè la più alta accuratezza), ripetendo ricorsivamente, fino a quando non avrà suddiviso con successo i dati in tutte le foglie (o raggiunto la massima profondità).
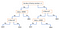
Gli alberi di decisione sono in generale semplici da capire e visualizzare, richiedendo poca preparazione dei dati. Questo metodo può anche gestire sia dati numerici che categorici. D’altra parte, gli alberi complessi non generalizzano bene (“overfitting”), e gli alberi di decisione possono essere un po’ instabili perché piccole variazioni nei dati possono portare alla generazione di un albero completamente diverso.
Un metodo di classificazione che è derivato dagli alberi di decisione è Random Forest, essenzialmente un “meta-estimatore” che adatta un certo numero di alberi di decisione su vari sottocampioni di set di dati e usa la media per migliorare la precisione predittiva del modello e controlla l’over-fitting. La dimensione del sottocampione è la stessa del campione di input originale – ma i campioni sono estratti con sostituzione.
Le Random Forests tendono a mostrare un alto grado di robustezza all’overfitting (>robustness al rumore nei dati), con un tempo di esecuzione efficiente anche in set di dati più grandi. Sono però più sensibili ai set di dati sbilanciati, essendo anche un po’ più complessi da interpretare e richiedendo più risorse computazionali.
Un altro classificatore popolare in ML è la Regressione Logistica – dove le probabilità che descrivono i possibili risultati di una singola prova sono modellati usando una funzione logistica (metodo di classificazione nonostante il nome):

Ecco come appare l’equazione logistica:
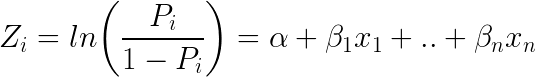
Prendendo e (esponente) su entrambi i lati dell’equazione si ottiene:
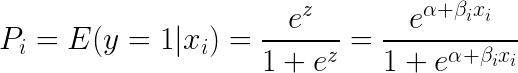
La regressione logistica è più utile per capire l’influenza di diverse variabili indipendenti su una singola variabile di risultato. Si concentra sulla classificazione binaria (per problemi con classi multiple, si usano estensioni della regressione logistica come la regressione logistica multinomiale e ordinale). La regressione logistica è popolare nei casi d’uso come l’analisi del credito e la propensione a rispondere/acquistare.
In ultimo, ma non meno importante, kNN (per “k Nearest Neighbors”) è anche spesso usato per problemi di classificazione. kNN è un semplice algoritmo che memorizza tutti i casi disponibili e classifica i nuovi casi sulla base di una misura di somiglianza (ad esempio, funzioni di distanza). È stato usato nella stima statistica e nel riconoscimento di modelli già all’inizio degli anni ’70 come tecnica non parametrica:

