La crescita dell’intelligenza artificiale (AI) ha ispirato più ingegneri del software, scienziati dei dati e altri professionisti a esplorare la possibilità di una carriera nel machine learning. Tuttavia, alcuni nuovi arrivati tendono a concentrarsi troppo sulla teoria e non abbastanza sull’applicazione pratica. Se hai intenzione di avere successo, hai bisogno di iniziare a costruire progetti di apprendimento automatico prima piuttosto che dopo.
Può essere difficile sapere da dove iniziare, quindi è sempre una buona idea cercare guida e ispirazione da altri. In questo post, condivideremo esempi reali di progetti di machine learning che ti aiuteranno a capire come dovrebbe essere un progetto completato. Forniremo anche consigli utili per creare i tuoi progetti di apprendimento automatico che attirano l’attenzione.
Se stai cercando una visione più completa delle opzioni di carriera nell’apprendimento automatico, dai un’occhiata alle nostre guide su come diventare uno scienziato dei dati e su come diventare un ingegnere dei dati.
Identificare i Twit su Twitter utilizzando l’elaborazione del linguaggio naturale (principiante)
I discorsi di odio sui social media e le fake news sono diventati fenomeni mondiali nell’era digitale. Mentre i post offensivi sono un problema, è ancora peggio quando sono imprecisi o erroneamente attribuiti a persone attraverso falsi profili.

(Fonte: Towards Data Science)
I progetti di apprendimento automatico possono aiutare. Un’applicazione popolare di elaborazione del linguaggio naturale (NLP) è l’analisi del sentimento. Questo permette a migliaia di documenti di testo di essere analizzati per determinati filtri in pochi secondi. Per esempio, Twitter può elaborare i post per commenti razzisti o sessisti e separare questi tweet dagli altri.
Eugene Aiken ha intrapreso un progetto per analizzare i post di due persone e determinare la probabilità che un tweet specifico provenga da un particolare utente. Per fare questo, ha usato i tweet di due noti rivali politici: Donald Trump e Hillary Clinton.
Questo ha comportato diverse fasi:
- Schiacciare i loro tweet
- Farli passare attraverso un processore di linguaggio naturale
- Classificarli con un algoritmo di apprendimento automatico
- Utilizzare il metodo predict-proba per determinare la probabilità
Con i risultati, Eugene ha potuto identificare quali tweet erano più e meno probabili di essere di Donald Trump. Questo stesso processo può essere usato per analizzare i tweet di chiunque, compresi i tuoi amici o familiari.
Puoi saperne di più su questo progetto di apprendimento automatico qui, e scaricare il set di dati qui.
Trovare le frodi mentre si affrontano i dati squilibrati (intermedio)
Quando il mondo si muove verso una realtà senza contanti e basata sul cloud, il settore bancario è più minacciato che mai. Il costo globale delle frodi con carta di credito dovrebbe salire oltre i 32 miliardi di dollari entro il 2020.
Anche se è un problema importante, le frodi rappresentano solo una frazione minima del numero totale di transazioni che avvengono ogni giorno. Questo dà origine a un altro problema: dati squilibrati.
Nel machine learning, la frode è vista come un problema di classificazione, e quando si ha a che fare con dati sbilanciati, significa che il problema da prevedere è in minoranza. Di conseguenza, il modello predittivo spesso fatica a produrre un reale valore di business dai dati, e a volte può sbagliare.
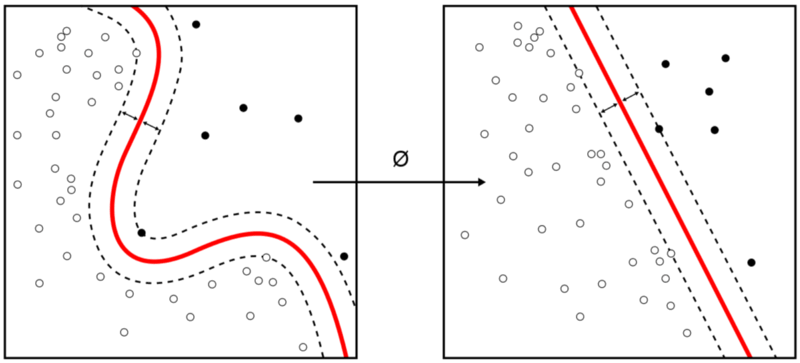
(Fonte: Towards Data Science)
Rafael Pierre spiega come il team Towards Data Science ha condotto un progetto per affrontare questo problema. Lavorando con un set di dati altamente squilibrato che aveva 492 frodi su 284.807 transazioni, hanno implementato tre diverse strategie:
- Oversampling
- Undersampling
- Un approccio combinato
Mentre ogni tecnica ha le sue virtù, l’approccio combinato ha colpito un punto dolce tra precisione e richiamo, offrendo effettivamente un alto livello di precisione quando si tratta di set di dati squilibrati.
Puoi saperne di più su questo progetto di apprendimento automatico qui.
Catturare i truffatori all’amo usando Geo-Mapping e Cloud Computing (Avanzato)
La vita marina vulnerabile è sotto immensa minaccia da bracconieri illegali in tutto il mondo. Per molti anni, era praticamente impossibile tenere sotto controllo le attività di ogni barca in mare. In questi giorni, i progressi in AI, geo-mapping e cloud computing si sono combinati per realizzare una brillante idea di progetto di apprendimento automatico: Global Fishing Watch.

(Fonte: Unsplash)
Quindi, come esattamente il machine learning sta aiutando Global Fishing Watch a identificare le attività di pesca illegali nei nostri oceani? Questo progetto in corso prevede tre fasi principali:
- Raccolta dei dati – La maggior parte delle grandi navi utilizza un dispositivo simile al GPS noto come sistema di identificazione automatica (AIS), che trasmette la loro posizione. Anche se molti pescherecci non hanno AIS, quelli che lo fanno rappresentano circa l’80% della pesca globale in alto mare. Tracciando i dispositivi AIS con i satelliti, è possibile monitorare i movimenti delle navi, anche in aree remote.
- Elaborazione – Global Fishing Watch utilizza reti neurali per elaborare le informazioni e trovare modelli in grandi set di dati. Questo comprende circa 60 milioni di punti di dati da oltre 300.000 navi, ogni giorno! Con l’aiuto di esperti di pesca, l’algoritmo ha imparato a classificare queste navi in base a una serie di fattori, quali:
- Tipo – vela, carico, pesca
- Attrezzatura da pesca – rete a strascico, palangaro, rete a circuizione
- Comportamenti di pesca – dove si trova, quando è attiva
- Condivisione dei risultati – Queste informazioni sul tracciamento delle navi sono disponibili al pubblico. Chiunque può visitare il sito web per tracciare i movimenti dei pescherecci commerciali in tempo reale, seguirli sulla mappa interattiva o scaricare i dati. Le persone possono anche creare mappe di calore per controllare i modelli di attività di pesca o visualizzare le tracce di navi specifiche in aree marine protette.
Puoi saperne di più su questo progetto di apprendimento automatico qui.
Uber aiuta il supporto clienti utilizzando l’apprendimento profondo (avanzato)
Come uno dei primi esempi di interruzione tecnologica, Uber intende rimanere nei paraggi. Con miliardi di corse da gestire ogni anno, l’app di ride-sharing ha bisogno di un fantastico sistema di supporto per risolvere i problemi dei clienti il più rapidamente possibile.
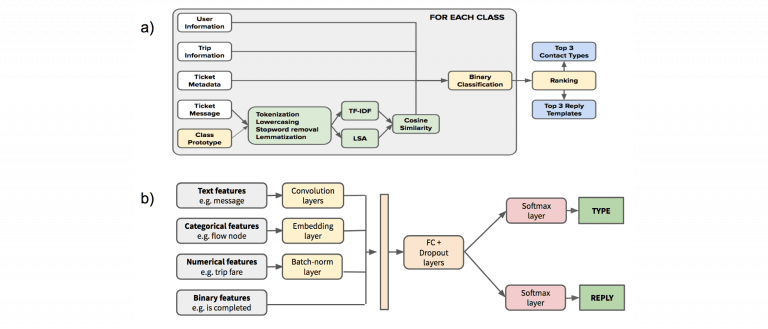
(Fonte: Uber)
Uber ha deciso di migliorare l’efficacia dei suoi rappresentanti del supporto clienti creando un’architettura modello “human-in-the-loop”, che è chiamata Customer Obsession Ticket Assistant, o COTA.
Testando due versioni di COTA, il team di Uber ha usato il deep learning per scoprire l’impatto sul tempo di gestione dei biglietti, la soddisfazione dei clienti e le entrate. È un ottimo modello per i progetti di deep learning che combinano l’architettura tecnica intelligente con l’input umano e si spera che vi fornisca altre idee di progetti di deep learning.
Puoi saperne di più su questo progetto di apprendimento automatico qui.
Barbie With Brains Using Deep Learning Algorithms (Advanced)
Le bambole moderne che possono “parlare” svolgono un ruolo importante nel formare le giovani menti dei bambini. Tuttavia, le bambole standard hanno tipicamente una serie limitata di frasi che non hanno alcuna correlazione con ciò che il bambino sta dicendo.
Ma se la bambola potesse capire le domande? E se la bambola potesse dare risposte logiche?

(Fonte: ToyTalk)
Hello Barbie è una dimostrazione eccitante del potere del machine learning e dell’intelligenza artificiale. Attraverso NLP e alcune analisi audio avanzate, Barbie può interagire in una conversazione logica. Il microfono sulla sua collana registra qualsiasi cosa venga detta e poi la trasmette ai server ToyTalk, dove viene analizzata.
Ci sono oltre 8.000 linee di dialogo disponibili, e i server trasmetteranno la risposta più appropriata entro un secondo in modo che Barbie possa rispondere. Considerala un’altra architettura che si aggiunge alla tua scorta di idee per progetti di deep learning.
Puoi saperne di più su questo progetto di apprendimento automatico qui.
Netflix Artwork Personalization Using AI (Advanced)
Netflix è la forza dominante nell’intrattenimento ora, e la società capisce che persone diverse hanno gusti diversi. A volte, le persone sono colpevoli di giudicare spettacoli o film dalle loro immagini e quindi potrebbero non controllare mai certi programmi. Per non essere sconfitto, Netflix mira a convincere più persone a guardare i loro spettacoli.

(Fonte: Unsplash)
Quando si visita Netflix, a volte si vedono opere d’arte diverse per gli stessi spettacoli. Questo è l’apprendimento automatico al lavoro. Netflix utilizza una rete neurale convoluzionale che analizza le immagini visive. L’azienda spiega che si basa anche su “banditi contestuali”, che lavorano continuamente per determinare quale opera d’arte ottiene un migliore coinvolgimento.
Con il tempo, man mano che usi Netflix più spesso, inizia a capire non solo quali programmi ti piacciono, ma anche quale tipo di opera d’arte! Per esempio, se hai visto diversi film con Uma Thurman, è probabile che tu veda l’arte di Pulp Fiction con l’attrice invece delle co-star John Travolta o Samuel L. Jackson.
Puoi saperne di più su questo progetto di apprendimento automatico qui.
Related: 6 Progetti Completi di Scienza dei Dati
Come generare le tue idee di progetto di apprendimento automatico
Se stai già imparando a diventare un ingegnere di apprendimento automatico, potresti essere pronto a darci dentro. Altrimenti, ecco alcuni passi per mettere in moto le cose.
Scegli un’idea che ti eccita
Per dare il via alle cose, hai bisogno di un brainstorming di idee per progetti di apprendimento automatico. Pensa ai tuoi interessi e cerca di creare concetti di alto livello intorno a questi. Scegli l’idea più fattibile, e poi solidificala con una proposta scritta, che agisce come un modello da controllare durante tutto il progetto.
Related: 5 Industrie non tradizionali che stanno sfruttando l’IA
Evitare di andare fuori portata
Se è il tuo primo progetto, dovresti combattere l’impulso di andare oltre lo scopo del progetto. Concentrati su semplici progetti di apprendimento automatico. Concentrandosi su un piccolo problema e ricercando un grande e rilevante set di dati, il vostro progetto ha maggiori probabilità di generare un ritorno positivo sul vostro investimento.
Testate la vostra ipotesi
Soprattutto quando si parla di progetti facili di apprendimento automatico per principianti, la cosa principale a cui pensare è generare intuizioni dal vostro progetto. Non preoccupatevi ancora di agire su queste intuizioni. Modellate la vostra ipotesi e testatela. Python è il linguaggio più semplice per i principianti, e vi consigliamo di usarlo per condurre i vostri test.
Implementare i risultati
Una volta che hai raggiunto tutti i risultati desiderati, puoi cercare di implementare il tuo progetto. Ci sono alcuni passi in questa fase:
- Creare un’API (application programming interface) – Questo ti permette di integrare le tue intuizioni di machine learning nel prodotto.
- Registrare i risultati su un unico database – Mettendo tutto insieme, è più facile costruire sui risultati.
- Incorpora il codice – Quando hai poco tempo, incorporare il codice è più veloce di un’API.
Rivedere e imparare
Quando hai finito il progetto, valuta i risultati. Pensate a cosa è successo e perché. Cosa avresti potuto fare diversamente? Col tempo, man mano che acquisisci esperienza, sarai in grado di imparare dai tuoi stessi errori.
Consigli per progetti di apprendimento automatico per principianti
Anche i semplici progetti di apprendimento automatico devono essere costruiti su una solida base di conoscenze per avere una reale possibilità di successo. Inoltre, il campo di gioco competitivo rende difficile per i nuovi arrivati distinguersi.
Relativo: Come ottenere uno stage di Machine Learning
Ecco alcuni consigli per far brillare il tuo progetto di machine learning.
Avere familiarità con le applicazioni comuni del Machine Learning
In generale, ci sono tre tipi fondamentali di machine learning:
- L’apprendimento supervisionato analizza i dati storici per prevedere nuovi risultati. Per esempio, prevedere i prezzi degli immobili.
- L’apprendimento non supervisionato cerca modelli di dati usando l’analisi statistica. Per esempio, identificando i segmenti di clienti all’interno dei dati di vendita della tua azienda.
- L’apprendimento per rinforzo opera con un modello dinamico che usa prove ed errori per migliorare costantemente le prestazioni. Per esempio, il trading azionario.
Quando svilupperai una migliore comprensione di queste applicazioni, saprai come applicare il machine learning al tuo problema.
Non sottovalutare la pre-elaborazione e la pulizia dei dati
I dati rumorosi possono alterare i tuoi risultati. Pertanto, si dovrebbe cercare di utilizzare regolarmente la pre-elaborazione e la pulizia dei dati. In parole povere, si tratta di prendere i vostri dati e renderli più facili da capire. Mettendo in ordine le cose e inserendo i dati mancanti, ti assicuri che i tuoi modelli siano il più accurati possibile. Se i vostri progetti sull’apprendimento automatico hanno problemi di qualità dei dati, l’articolo collegato prima dovrebbe aiutare con le basi della gestione dei dati con idee di progetti di apprendimento automatico.
L’apprendimento automatico è un gioco di squadra
Anche Neo aveva bisogno di amici. Quando stai sviluppando progetti di apprendimento automatico, avrai bisogno di lavorare con altre persone, molte delle quali non avranno la tua stessa comprensione dell’IA e del software.
Devi fidarti degli altri ed essere onesto sul tuo modello. In definitiva, quando stai lavorando su progetti di apprendimento automatico, punta alla trasparenza e alla comunicazione aperta in modo che il tuo progetto possa funzionare senza problemi.
Focalizzarsi sulla soluzione di problemi del mondo reale
Va bene usare l’apprendimento automatico per applicazioni divertenti, ma se hai gli occhi su un lavoro come ingegnere di apprendimento automatico, dovresti concentrarti sull’alleviare un punto dolente sentito da un sacco di persone. Pensa a come il tuo progetto offrirà valore ai clienti. Ricercando i problemi del mondo reale, puoi far risaltare il tuo progetto come uno che il mondo vuole e di cui ha bisogno. Non inventate progetti di deep learning solo per mostrare le vostre abilità – create un impatto significativo con qualsiasi tecnologia possiate usare. È l’impatto e non la tecnologia che conta veramente.
Sfrutta i tuoi punti di forza
Se sei nuovo nell’apprendimento automatico e non hai molta esperienza, può essere un po’ scoraggiante confrontarsi con codificatori e ingegneri software veterani. In questo caso, la tua debolezza percepita può essere una forza. Puoi far leva sul tuo background e sulla tua precedente conoscenza di diversi settori per creare progetti unici di apprendimento automatico a cui molte altre persone potrebbero non pensare. Puoi generare idee per progetti di apprendimento automatico con la tua prospettiva guardando anche i set di dati aperti.
L’apprendimento automatico può rendere il mondo più umano
L’industria dell’apprendimento automatico continuerà a crescere negli anni a venire. Mentre alcune persone vedono la cosiddetta “ascesa dei robot” come la fine del tocco personale negli affari, la realtà è proprio l’opposto. Ci sono così tante grandi idee di progetti di apprendimento automatico che in realtà aiutano le aziende a offrire un servizio migliore, umanizzando efficacemente i marchi rendendoli più in sintonia con gli interessi del loro pubblico di riferimento.
Non è facile sviluppare le tue prime idee di progetto di apprendimento automatico. Imparando dagli altri, è possibile creare qualcosa di grande. I progetti sull’apprendimento automatico possono avere effetti drammatici su campi diversi e importanti come la salute umana e l’economia: i progetti sull’apprendimento automatico possono aiutare a far progredire la nostra comprensione di noi stessi e del nostro mondo.
Il Machine Learning Engineering Career Track di Springboard, il primo del suo genere a venire con una garanzia di lavoro, si concentra sull’apprendimento basato su progetti. Per saperne di più.
