はじめに
Picture this – あなたは次期iPhoneの価格予測を任されており、過去のデータを提供されています。 これは、四半期ごとの売上、前月比の支出、および Apple の貸借対照表に付随するあらゆるもののような機能を含みます。 データサイエンティストとして、これはどのような問題に分類されるでしょうか。 もちろん、時系列モデリングです。
製品の売上予測から家庭の電力使用量の推定まで、時系列予測は、マスターしないまでも、データサイエンティストが知っておくべきコアスキルの 1 つです。
まず、ARIMA の概念を理解し、メイン トピックである自動 ARIMA につなげていきます。
目次
- 時系列とは
- 時系列予測の方法
- ARIMA入門
- ARIMA実装ステップ
- なぜAutoARIMAが必要か?
- 自動ARIMAの実装(航空旅客データセット)
- 自動ARIMAはどのようにパラメータを選択するのか
時系列とその手法(移動平均、指数平滑化、ARIMAなど)に慣れていれば、4節まで直接読み飛ばすことができます。
時系列とは
時系列データを扱う技法を学ぶ前に、まず時系列とは何か、他の種類のデータとどう違うかを理解する必要があります。 時系列とは、一定の時間間隔で測定された一連のデータポイントである」というのが、時系列の正式な定義です。 これは、特定の値が、1時間ごと、毎日、毎週、10日ごとなど、一定の間隔で記録されていることを意味します。 時系列と異なる点は、時系列の各データポイントが前のデータポイントに依存していることである。
例 1:
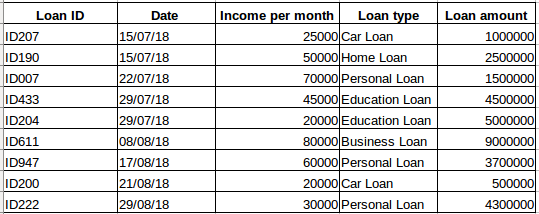
ある会社からローンを組んだ人のデータセットがあるとします(下の表に示すとおり)。 各行が前の行と関連していると思いますか? そうではありません。 ローンを組んだ人は、その人の経済状況やニーズに基づいています(家族の人数など他の要因も考えられますが、ここでは簡単のために収入とローンの種類だけを考えています)。 また、このデータは特定の時間間隔で収集されたものではありません。 9303>
例2:
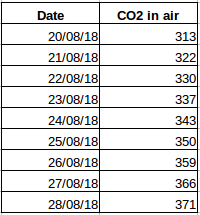
別の例を見てみましょう。 1 日あたりの空気中の CO2 のレベルを含むデータセットがあるとします (下のスクリーンショット)。 過去数日間の値を見て、翌日のおおよその CO2 量を予測できるでしょうか。 まあ、もちろんです。 9303>
もう直感的に分かったと思いますが、最初のケースは単純な回帰の問題で、2番目は時系列の問題です。 ここでの時系列のパズルは、線形回帰を使用して解くこともできますが、それは値の相対的な過去のすべての値との関係を無視するため、実際には最良のアプローチではありません。 それでは、時系列問題を解くためによく使われるテクニックをいくつか見ていきましょう。
時系列予測のための方法
時系列予測のための方法はいくつかありますが、このセクションではそれらを簡単に説明します。 以下のすべての手法の詳細な説明とpythonコードは、この記事で見ることができます。 7 techniques for time series forecasting (with python codes).
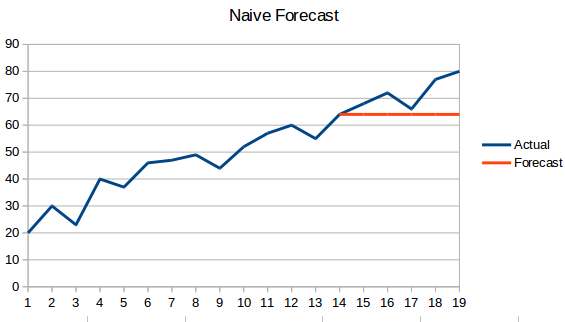
- Naive Approach.時系列予測の7つの手法(pythonコード付き)。 この予測手法では、新しいデータポイントの値は、以前のデータポイントと等しくなるように予測されます。 すべての新しい値が以前の値を取るので、結果は平らな線になります。
- 単純平均。 次の値は、前のすべての値の平均として取られます。 この方法は、平坦な線にならないので、「ナイーブ・アプローチ」よりも良い予測ですが、ここでは、過去のすべての値が考慮されるので、必ずしも有用ではないかもしれません。 例えば、今日の気温を予測するように言われたら、1ヶ月前の気温ではなく、過去7日間の気温を考慮します。
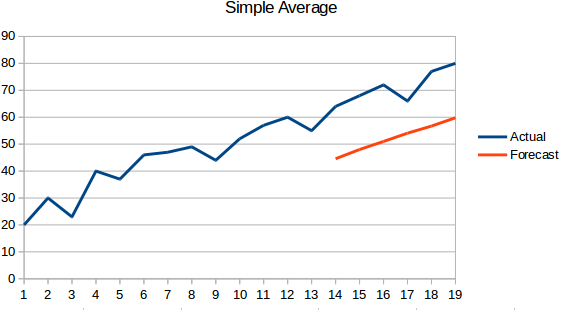
- 移動平均:これは前の手法より改善されたものです。 過去のすべてのポイントの平均を取るのではなく、過去の「n」個のポイントの平均を予測値とします。

- 加重移動平均 : 加重移動平均は、過去の「n」個の値に異なる重みを付けた移動平均です。
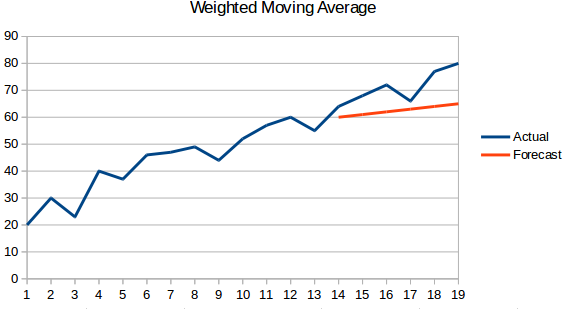
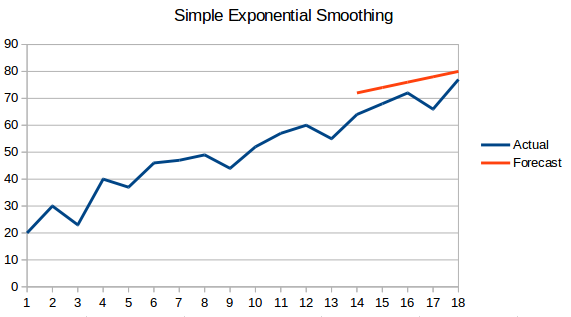
- 単純指数平滑化:この手法では、遠い過去からの観測値よりも最近の観測値に大きな重みが割り当てられます。
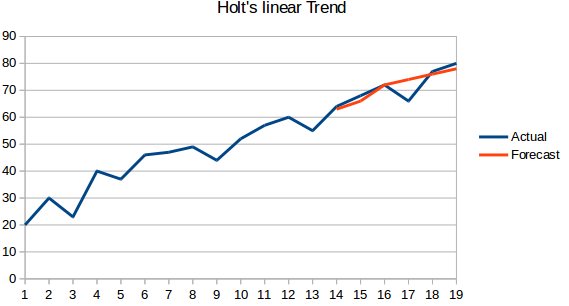
- Holtの線形トレンドモデル:Holtの線形トレンドモデル。 この方法は、データセットの傾向を考慮する。 トレンドというのは,系列の増加または減少の性質を意味する. 例えば、あるホテルの予約数が毎年増加しているとすると、予約数は増加傾向を示していると言うことができる。 この手法の予測関数は、水準とトレンドの関数です。
- Holt Winters Method: このアルゴリズムは、系列のトレンドと季節性の両方を考慮に入れています。 例えば、ホテルの予約数は週末に多く、平日は少なく、毎年増加する。週ごとの季節性と増加傾向がある。 これはデータポイント間の相関を記述し、値の差を考慮するものである。 ARIMAを改良したものにSARIMA(または季節性ARIMA)があります。
ARIMA入門
このセクションでは、Auto Arimaを理解するのに役立つARIMAを簡単に紹介します。 有馬の詳細な説明、パラメータ(p、q、d)、プロット(ACF PACF)、および実装はこの記事に含まれています。 Complete tutorial to Time Series.
ARIMA は時系列予測のための非常に一般的な統計手法です。 ARIMAはAuto-Regressive Integrated Moving Averagesの略です。 ARIMAモデルは、次のような前提で動作します –
- データ系列は定常であり、平均と分散は時間とともに変化してはならないことを意味します。
ARIMAには、AR(自己回帰項)、I(差分項)、MA(移動平均項)の3つの構成要素があります。 AR項とは、次の値を予測するために使われる過去の値のことです。 AR項はarimaのパラメータ’p’で定義されます。 pの値はPACFプロットを使って決定されます。
ARIMA実装のためのステップ
ARIMAモデルを実装するための一般的な手順は –
- データをロードします。 モデル構築の最初のステップは、もちろんデータセットをロードすることです
- 前処理を行う。 データセットに応じて、前処理のステップを定義する。 これはタイムスタンプの作成、日付/時間列のd型の変換、系列を一変量にすること等を含む。 仮定を満たすために、系列を定常化する必要があります。 これには系列の定常性を確認し、必要な変換を行うことが含まれる
- d値を決定する。 系列を定常化するために、差分演算を行った回数をd値とする
- ACFプロットとPACFプロットを作成する。 これはARIMAの実装で最も重要なステップである。 ACF PACFプロットは、ARIMAモデルの入力パラメータを決定するために使用される
- pとqの値を決定する。 前のステップでプロットからpとqの値を読み取る
- ARIMAモデルを適合させる。 処理したデータと前のステップで計算したパラメータ値を使って、ARIMAモデルをあてはめる
- 検証セットで値を予測する。 将来の値を予測する
- RMSEを計算する:モデルのパフォーマンスを確認するために、検証セットの予測値と実際の値を使用してRMSE値をチェックする
Why do we need Auto ARIMA?
ARIMAは時系列データの予測に非常に強力なモデルですが、データ準備とパラメータチューニングは本当に時間がかかってしまうのです。 ARIMAを実装する前に、系列を静止させ、上で説明したプロットを使用してpとqの値を決定する必要があります。 Auto ARIMAを使えば、前のセクションで見たステップ3から6を省くことができるので、この作業は本当に簡単です。 以下は、自動ARIMAを実装するための手順です。
- データをロードします。 このステップは同じになります。 ノートブックにデータを読み込む
- データの前処理をする。 入力は一変量でなければならないので、他の列は削除する
- Fit Auto ARIMA: 一変量系列にモデルをあてはめる
- Predict values on validation set: 検証セットで値を予測する。 検証セットで予測を行う
- Calculate RMSE: 実際の値に対する予測値を使用してモデルのパフォーマンスをチェックする
ご覧のように、pとqの特徴の選択を完全に回避することが出来ました。 なんということでしょう。
Implementation in Python and R
International-Air-Passenger datasetを使用します。 このデータセットには、毎月の乗客数(単位:千人)の合計が格納されています。 月と旅客数の2つの列があります。
#load the datadata = pd.read_csv('international-airline-passengers.csv')#divide into train and validation settrain = datavalid = data#preprocessing (since arima takes univariate series as input)train.drop('Month',axis=1,inplace=True)valid.drop('Month',axis=1,inplace=True)#plotting the datatrain.plot()valid.plot()
#building the modelfrom pyramid.arima import auto_arimamodel = auto_arima(train, trace=True, error_action='ignore', suppress_warnings=True)model.fit(train)forecast = model.predict(n_periods=len(valid))forecast = pd.DataFrame(forecast,index = valid.index,columns=)#plot the predictions for validation setplt.plot(train, label='Train')plt.plot(valid, label='Valid')plt.plot(forecast, label='Prediction')plt.show()
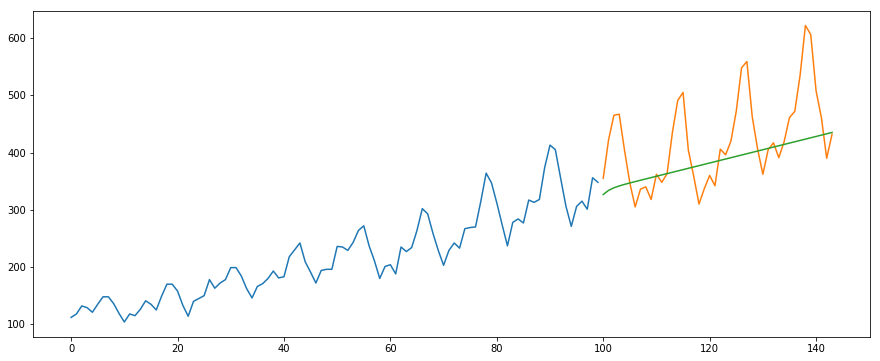
#calculate rmsefrom math import sqrtfrom sklearn.metrics import mean_squared_errorrms = sqrt(mean_squared_error(valid,forecast))print(rms)
output -76.51355764316357
以下は同じ問題のRコードです:
# loading packageslibrary(forecast)library(Metrics)# reading datadata = read.csv("international-airline-passengers.csv")# splitting data into train and valid setstrain = datavalid = data# removing "Month" columntrain$Month = NULL# training modelmodel = auto.arima(train)# model summarysummary(model)# forecastingforecast = predict(model,44)# evaluationrmse(valid$International.airline.passengers, forecast$pred)
How does Auto Arima select the best parameters
上記のコードにおいて、我々は単に、.NETを使用していました。fit() コマンドを使用して、p、q、d の組み合わせを選択することなく、モデルを適合させました。しかし、モデルはどのようにしてこれらのパラメーターの最適な組み合わせを見つけ出すのでしょうか。 Auto ARIMAでは、生成されたAIC値とBIC値を考慮して(コードにあるように)パラメータの最適な組合せを決定します。 AIC (Akaike Information Criterion) と BIC (Bayesian Information Criterion) 値は、モデルを比較するための推定量です。 これらの値が低いほど、良いモデルです。
AIC および BIC の背後にある数学に興味がある場合は、これらのリンクをチェックしてください。
End Notes and Further Reads
自動 ARIMA が時系列予測を行うための最も簡単なテクニックであるとわかってきました。 近道を知っていることは良いことですが、その背後にある数学に精通することも重要です。 この記事では、ARIMA がどのように機能するかの詳細についてざっと説明しましたが、記事内で提供されているリンクに必ず目を通してください。
- A Comprehensive Guide to Time Series Forecast in Python
- Complete Tutorial to Time series in R
- 7 techniques for time series forecasting (with python codes)
ここで学んだことは演習問題で練習してください: Time Series Practice Problem. また、同じ練習問題「時系列予測」で作成したトレーニングコースも受講していただくと、より効果的なスタートが切れるでしょう。