人工知能 (AI) の成長により、多くのソフトウェア エンジニア、データ科学者、その他の専門家が、機械学習でのキャリアの可能性を探るようになりました。 しかし、一部の新参者は、理論に焦点を当てすぎて、実践的なアプリケーションに十分な注意を払わない傾向があります。 成功するためには、機械学習プロジェクトの構築を早急に開始する必要があります。あなたのポートフォリオを向上させるために、機械学習プロジェクトのアイデアが必要です。
何から始めたらよいかを知るのは難しいので、他の人から指導やインスピレーションを求めるのは常に良い考えです。 この投稿では、完成したプロジェクトがどのように見えるかを理解するのに役立つ、機械学習プロジェクトの実例を共有します。 また、注目を集める独自の機械学習プロジェクトを作成するための実用的なヒントも提供します。
機械学習のキャリアオプションについてより包括的な洞察をお探しの場合は、データサイエンティストになる方法とデータエンジニアになる方法のガイドをご覧ください。
自然言語処理によるTwitterでのツイートの特定(初心者)
ソーシャルメディア上の憎悪表現や偽ニュースは、デジタル時代における世界規模の現象となっています。 攻撃的な投稿は問題ですが、それが不正確であったり、偽のプロフィールによって間違って人々に帰属していたりすると、さらに悪いことになります。

(Source: Towards Data Science)
機械学習に関するプロジェクトが役に立ちます。 自然言語処理 (NLP) の一般的なアプリケーションは、センチメント分析です。 これにより、何千ものテキスト ドキュメントを数秒のうちに特定のフィルター用にスキャンすることができます。 たとえば、Twitter では、人種差別的または性差別的な発言に関する投稿を処理し、これらのツイートを他のものと分離することができます。
Eugene Aiken氏は、2人の投稿を分析し、特定のツイートがある特定のユーザーからのものである確率を決定するプロジェクトを実施しました。 そのために、彼は2人の有名な政治的ライバルのツイートを使用しました。 ドナルド・トランプとヒラリー・クリントンです。
これにはいくつかの段階がありました。
- ツイートをスクレイピング
- 自然言語処理
- 機械学習アルゴリズムで分類
- 確率を求めるために予測プロバ法
その結果、ユージーンはどのツイートが最もドナルド・トランプからで、最も低い可能性があるかを識別することができたのです。 この同じプロセスは、友人や家族など、誰からのツイートでも分析できます。
この機械学習プロジェクトについての詳細はこちら、データセットはこちらからダウンロードできます。
不正を発見しながら不均衡データに取り組む(中級)
世界がキャッシュレス、クラウド・ベースの現実に向かっている中、銀行部門はかつてないほど脅威に晒されています。 クレジットカード詐欺の世界的なコストは、2020年までに320億ドルを超えて急増すると予想されています。
大きな問題ではありますが、不正行為が占める割合は、毎日行われる取引の総数のごく一部に過ぎません。 そのため、「データのバランスが悪い」という別の問題が生じています。
機械学習では、不正は分類問題とみなされ、アンバランスなデータを扱うときは、予測すべき問題が少数派であることを意味します。 その結果、予測モデルはデータから本当のビジネス価値を生み出すのに苦労することが多く、時には間違ってしまうこともあります。
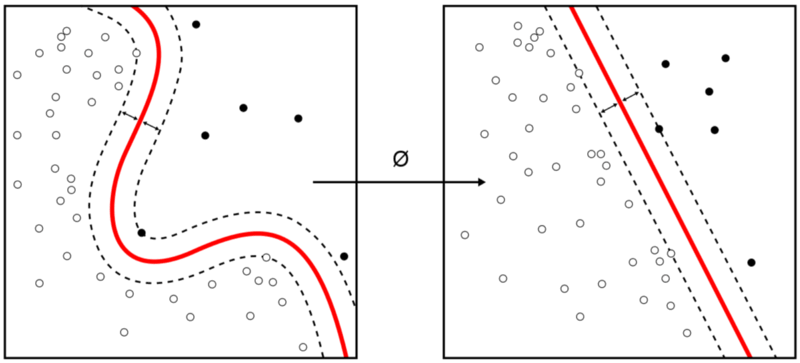
(Source: Towards Data Science)
Rafael Pierre は、Towards Data Science チームがこの問題に取り組むプロジェクトを実施した方法を説明しています。 284,807件のトランザクションのうち492件が不正であるという、非常に不均衡なデータセットを使って、彼らは3つの異なる戦略を実施しました:
- Oversampling
- Undersampling
- A combined approach
それぞれのテクニックには利点がありますが、コンビネーションアプローチは精度と再現率のスイートスポットに当たり、バランスの悪いデータセットでも高いレベルの精度を効率よく提供することができました。
この機械学習プロジェクトについては、こちらをご覧ください。
Catch Crooks on the Hook Using Geo-Mapping and Cloud Computing (Advanced)
脆弱な海洋生物は、世界中で違法密猟者の巨大な脅威にさらされています。 長年にわたり、海上のすべての船の活動を監視することは事実上不可能だった。 最近では、AI、ジオマッピング、クラウドコンピューティングの進歩が相まって、素晴らしい機械学習プロジェクトのアイディアが実現しました。 Global Fishing Watch.

(Source: Unsplash)
では、機械学習は、Global Fishing Watchが海での違法漁業を特定するのに、いったいどのように役立っているのでしょうか? 現在進行中のこのプロジェクトには、主に3つの段階があります:
- データの取得 – ほとんどの大型船は、自動識別システム(AIS)と呼ばれるGPSのような装置を使用しており、自分の位置を放送しています。 多くの漁船はAISを搭載していませんが、搭載している漁船は世界の公海漁業の約8割を占めています。 AIS装置を衛星で追跡することで、遠隔地でも船の動きを監視することが可能です。
- 処理 – Global Fishing Watchは、ニューラルネットワークを使って情報を処理し、大規模なデータセットの中からパターンを見つけ出しています。 これは、毎日30万隻以上の船から得られる約6000万点のデータから構成されています。 漁業の専門家の助けを借りて、アルゴリズムはこれらの船舶を多くの要因で分類する方法を学びました。
- タイプ – 帆、貨物、漁業
- 漁具 – グロール、延縄、巻き網
- 漁業行動 – どこにいて、いつ活動しているか
- 結果の共有 – この船の追跡情報は一般に公開されているものです。 誰でもこのウェブサイトにアクセスし、商業漁船の動きをリアルタイムで追跡したり、インタラクティブな地図で追跡したり、データをダウンロードしたりすることができます。 また、ヒートマップを作成し、漁業活動のパターンをチェックしたり、海洋保護区域における特定の船舶の航跡を表示したりすることもできます。
この機械学習プロジェクトについては、こちらをご覧ください。
Uber Helpful Customer Support Using Deep Learning (Advanced)
技術的破壊の代表例の1つとして、Uberは今後も存続するつもりでいます。 毎年何十億もの乗り物を処理するため、ライドシェアリング アプリは、顧客の問題をできるだけ早く解決するための素晴らしいサポート システムを必要としています。
(Source: Uber)
Uberは、「ヒューマン イン ザ ループ」モデルのアーキテクチャを構築して顧客サポート担当者の効果を改善しようとし、これは、「カスタマー オブセッション チケットアシスタント」、すなわちCOTAと呼ばれています。
Uberチームは、COTAの2つのバージョンを分割テストすることにより、チケット処理時間、顧客満足度、および収益への影響を発見するために、ディープラーニングを使用しました。 これは、巧妙な技術的アーキテクチャと人間の入力を組み合わせた深層学習プロジェクトの素晴らしいモデルであり、うまくいけば、他の深層学習プロジェクトのアイデアを提供することができます。
この機械学習プロジェクトについては、こちらで詳しく説明しています。
ディープ ラーニング アルゴリズムを使用して脳を持つバービー(上級)
「話す」ことができる現代の人形は、子供たちの若い心を形成する上で重要な役割を担っている。 しかし、標準的な人形は一般的に、子供が言っていることと相関関係のない限られたフレーズしか持っていない。
しかし、もし人形が質問を理解できたらどうでしょう。

(出典: ToyTalk)
Hello Barbie は、機械学習と人工知能の力を示す、エキサイティングなデモンストレーションです。 NLP といくつかの高度な音声分析により、バービーは論理的な会話をすることができます。 首飾りのマイクで会話を録音し、トイトークのサーバーに送信して、そこで分析されます。
8,000以上のセリフが用意されていて、サーバーが1秒以内に最も適切な返答を送信し、バービーがそれに応えられるようにします。 深層学習プロジェクトのアイデアの宝庫を増やす、もう一つのアーキテクチャとお考えください。
この機械学習プロジェクトについては、こちらで詳しく説明しています。
Netflix Artwork Personalization Using AI (Advanced)
Netflixは、現在エンターテインメントにおいて圧倒的な力を誇っており、同社は、人によって好みが異なるということを理解しています。 時には、番組や映画を画像で判断することに罪悪感を持つ人もいるため、特定の番組をチェックすることがない場合もある。 3993>

(Source: Unsplash)
Netflixにアクセスすると、同じ番組で異なるアートワークを目にすることがあります。 これは、機械学習が働いているのです。 Netflixは、視覚的なイメージを分析する畳み込みニューラルネットワークを使用しています。 同社は、どのアートワークがより良いエンゲージメントを得られるかを継続的に判断する「コンテクスチュアル バンディット」にも依存していると説明しています。
Netflixを使い続けるうちに、あなたがどの番組を好むかだけでなく、どのタイプのアートワークも理解し始めるのです!
Netflixは、あなたが好きな番組と、そのアートワークを理解するようになります。 たとえば、ユマ サーマン主演の映画を何本か見たことがある場合、共演者のジョン トラボルタやサミュエル L. ジャクソンではなく、この女優をフィーチャーしたパルプ フィクションのアートを見る可能性があります。
この機械学習プロジェクトについてもっと知ることができます。 6 Complete Data Science Projects
How to Generate Your Own Machine Learning Project Ideas
すでに機械学習エンジニアになるための学習を行っている方は、そろそろ取り掛かる準備ができているかもしれませんね。
Pick an Idea That Excites You
物事を開始するには、いくつかの機械学習プロジェクトのアイデアをブレインストーミングする必要があります。 自分の興味について考え、それに関する高レベルのコンセプトを作成することを検討してください。 最も実行可能なアイデアを選び、提案書でそれを固め、プロジェクト全体を通してチェックするための青写真の役割を果たします。 AIを活用する5つの非伝統的な産業
範囲外を避ける
初めてのプロジェクトであれば、範囲を超えようとする衝動を抑えるべきでしょう。 シンプルな機械学習プロジェクトに集中しましょう。 小さな問題に焦点を当て、大規模な関連データセットを調査することで、プロジェクトは投資に対してプラスのリターンを生み出す可能性が高くなります。
仮説を検証する
特に、初心者向けの簡単な機械学習プロジェクトについて話す場合、主に考えるべきことは、プロジェクトから洞察を生み出すことです。 それらの洞察に基づいて行動することについては、まだ心配しないでください。 仮説をモデル化し、それを検証することです。 Pythonは初心者に最も易しい言語ですので、Pythonを使ってテストを行うことをお勧めします。
結果を実装する
すべての望ましい結果に到達したら、プロジェクトの実装に目を向けることができます。 この段階にはいくつかのステップがあります。
- API (アプリケーション プログラミング インターフェイス) を作成する – これにより、機械学習の洞察を製品に統合することができます。
- 結果を単一のデータベースに記録する – すべてを照合することで、結果を基にした構築を容易にします。
- コードを埋め込む – 時間がないときは、APIよりもコードを埋め込む方が速い。
Revise and Learn
プロジェクトが終了したら、発見を評価します。 何が起こったのか、そしてなぜ起こったのかを考えてください。 何が違っていたのでしょうか。 3993>
初心者のための機械学習プロジェクトのヒント
簡単な機械学習プロジェクトでさえ、成功の本当のチャンスを得るためには、しっかりとした知識の基礎の上に構築される必要があります。 さらに、競争の激しい競技場であるため、新人が目立つことは困難です。
関連する記事
Get Familiar With the Common Applications of Machine Learning
大きく分けて、機械学習には3つの基本タイプがある:
- Supervised Learningは、新しい結果を予測するために過去のデータを分析する。 たとえば、不動産価格の予測など。
- 教師なし学習は、統計的な分析を用いてデータのパターンを探します。 例えば、会社の販売データから顧客セグメントを特定する。
- 強化学習は、常にパフォーマンスを向上させるために試行錯誤を行う動的なモデルで動作します。 例えば、株式取引など。
これらのアプリケーションの理解を深めることで、問題に機械学習を適用する方法がわかるようになります。
データの前処理とクリーニングを軽視しない
ノイズの多いデータは結果を歪ませる可能性があります。 したがって、データの前処理とデータ クリーニングを定期的に使用することを検討する必要があります。 簡単に言うと、これは、データを取って理解しやすくすることです。 データを整理し、欠損データを入力することで、モデルを可能な限り正確にすることができます。 機械学習のプロジェクトにデータ品質の問題がある場合、前のリンク先の記事が、機械学習プロジェクトのアイデアでデータ整理の基本を手助けしてくれるはずです。
Machine Learning Is a Team Game
Even Neo needed friends(ネオにさえ友人が必要だった)。 機械学習プロジェクトを開発するときは、他の人と一緒に作業する必要があります。その多くは、AIやソフトウェアについて自分と同じように理解しているわけではありません。
他の人を信頼し、また自分のモデルについて正直である必要があります。
Focus on Solving Real-World Problems
機械学習を楽しいアプリケーションに使うのは良いことだが、機械学習エンジニアとしての就職を視野に入れているなら、多くの人が感じているペインポイントを解消することに焦点を当てるべきである。 自分のプロジェクトが顧客にどのような価値を提供できるかを考えてみてください。 現実の問題を研究することで、あなたのプロジェクトが世の中に必要とされているものであることを際立たせることができます。 自分のスキルを誇示するためにディープラーニングのプロジェクトを思いつくだけでなく、できる限りの技術を使って意味のあるインパクトを生み出してください。 真に重要なのはインパクトであって、技術ではないのです。
自分の強みを生かす
機械学習の初心者で経験があまりない場合、ベテランのコーダーやソフトウェアエンジニアと対戦するのは少し気が引けるかもしれません。 この場合、あなたの認識された弱点が強みになることがあります。 自分の経歴やさまざまな業界に関するこれまでの知識を活かして、他の多くの人が考えもつかないようなユニークな機械学習プロジェクトを生み出すことができます。 オープンなデータセットも見ることで、独自の視点で機械学習プロジェクトのアイデアを生み出すことができます。
機械学習は世界をより人間らしくすることができる
機械学習業界は今後何年も成長し続けるでしょう。 いわゆる「ロボットの台頭」を、ビジネスにおけるパーソナルタッチの終焉と見る向きもありますが、現実はまったく逆です。 実際に企業がより良いサービスを提供するのに役立つ、素晴らしい機械学習プロジェクトのアイデアが非常に多くあり、ターゲットオーディエンスの興味に同調させることで、ブランドを効果的に人間化することができます。
最初の機械学習プロジェクトのアイデアを開発するのは簡単ではありません。 他の人から学ぶことで、素晴らしいものを生み出すことができるのです。 機械学習のプロジェクトは、人間の健康や経済など、多様で重要な分野に劇的な影響を与えることができます。機械学習のプロジェクトは、私たち自身とこの世界についての理解を深めるのに役立ちます。
Springboardの機械学習工学キャリアトラックは、この種のものとしては初めて雇用保証付きで、プロジェクトベースの学習に重点を置いています。

もっと詳しく知る。