De manier waarop wij denken in een moderne, post-industriële wereld wordt gekenmerkt door toenemende conceptuele abstractie. De wetenschappelijke methode heeft onze wereld getransformeerd, en heeft de manier waarop wij dagelijks over de wereld denken veranderd. Piaget noemde dit het formele operationele stadium: we denken door het manipuleren van abstracte concepten, los van voorbeelden uit het echte leven. Dit was absoluut vreemd voor onze niet al te verre voorouders, zoals blijkt uit experimenten in afgelegen dorpen in de Sovjet-Unie aan de vooravond van de industrialisatie.
Abstractie is overal: terwijl het woord procent nog maar 100 jaar geleden bijna nergens voorkwam, duikt het nu op rond elk 5000ste woord in de gemiddelde Engelse tekst, goed voor 0,02 procent van alle woorden.
In zekere zin worden we gedwongen tot abstract denken: we leven in een wereld die anders is dan die van onze evolutionaire voorouders, en het zijn vooral onze vermogens voor conceptueel denken die proberen gelijke tred te houden met de snelheid waarmee onze omgeving verschuift, en naar wat voor digitale, op kennis gebaseerde sferen die verschuift. Maar het is geen triviale taak. Onze hersenen zijn niet geoptimaliseerd om rationeel en objectief te zijn: Wikipedia somt zo’n 200 cognitieve biases op, psychologische patronen waarin onze waarneming de werkelijkheid vervormt en ons ervan weerhoudt rationeel te oordelen.
Het valse vertrouwen van getallen
De wereld, zoals we die tegenkomen, is onzeker. Moderne neurowetenschappelijke theorieën zien onze hersenen als apparaten die voortdurend proberen optimale beslissingen te nemen onder onzekere omstandigheden.
In een tijd waarin een pandemie zich over de wereld verspreidt en levens, banen en het sociale leven zoals wij dat kennen bedreigt, is onzekerheid alomtegenwoordig.
De abstractie van de wereld ontdoet ons van de ruis en het gekletter van de werkelijkheid, en veinst een gevoel van objectiviteit tegenover onzekerheid. Getallen geven ons een indruk van onaantastbaarheid, van iets stabiels om ons aan vast te houden. Ze geven ons een geruststellend gevoel, en waarom zouden ze dat niet doen? Getallen zijn een enorm nuttig instrument gebleken om orde in de wereld te scheppen, om haar met groot succes te manipuleren. Ze zijn misschien wel de belangrijkste technologische vooruitgang die de mensheid heeft geboekt sinds de ontdekking van het vuur.
Maar getallen zijn niet altijd gelijk aan getallen. Getallen komen met een inherent risico: abstractie is moeilijk, wetenschappelijk onderzoek is moeilijk, en getallen kunnen de strijd achter hun ontstaansgeschiedenis verbergen, de onzekerheid van de oorsprong achter de halo van objectieve waarheid die ze uitstralen.
De moeilijkheden van de statistiek
Statistiek, volgens Wikipedia, betreft het verzamelen, organiseren, analyseren, interpreteren en presenteren van gegevens.
Getallen zijn een van de centrale manieren om gegevens weer te geven. En veel getallen zweven tegenwoordig rond in de media en het publieke debat: sterftecijfers, totale aantallen gevallen, R0-factoren, schattingen van de effectiviteit van tegenmaatregelen…maar heel vaak liggen daar onbeantwoorde vragen achter op de loer.
Voordat je aanneemt wat gegevens je vertellen over de objectieve staat van de werkelijkheid, moeten eerst een aantal belangrijke vragen worden beantwoord:
- Hoe zijn de gegevens verzameld en georganiseerd?
- Hoe worden ze gepresenteerd?
- Hoe moeten ze worden geïnterpreteerd?
Het belang van gegevensverzameling
Covid-19 is een bijna ongekende uitdaging voor de wereldgemeenschap (laten we het maar niet over klimaatverandering hebben…) en doet mensen over de hele wereld hun collectieve adem inhouden. Dus in deze omgeving is het niet meer dan natuurlijk om te zoeken naar getallen die ons een gevoel van zekerheid geven over wat er werkelijk aan de hand is.
Maar de maatregelen die zijn genomen om de verspreiding van het virus te beteugelen zijn geen wetenschappelijk experiment, en dus moeten we heel voorzichtig zijn om het als een te behandelen. Er zijn verschillende punten waarop het testen op het virus sterk afwijkt van een echt experiment, en waarop vooroordelen binnenstromen. Het is zeer belangrijk in gedachten te houden dat dit in feite het geval is en dat de cijfers met een flinke korrel zout moeten worden genomen.
- Wie wordt er getest? Het overwegend testen van mensen die uit “hoog-risico gebieden” komen (zoals Iran, Italië en China) veroorzaakt een vertekening van de selectiegroep, wat leidt tot een scheve verdeling die aangeeft dat de meeste mensen uit hoog-risico gebieden zijn besmet, terwijl mensen van elders dat ook kunnen zijn, maar onopgemerkt blijven.
- Vergelijking van aantallen tussen landen is van beperkte waarde omdat het aantal tests van land tot land sterk verschilt. Terwijl Zuid-Korea op zijn hoogtepunt ongeveer 10000 tests per dag heeft uitgevoerd, en Duitsland niet ver achter dat aantal ligt, testen andere landen veel minder en sporen zij dienovereenkomstig veel kleinere aantallen besmettingen op.
- Op sommige plaatsen neemt gedurende bepaalde perioden, terwijl het aantal patiënten met een bevestigde Covid-19 infectie exponentieel toeneemt, ook het aantal tests snel toe. In principe zou dit kunnen leiden tot een grote groei in opsporingen, zelfs als het aantal besmette mensen constant blijft.
- Veel mensen hebben bijna geen symptomen of slechts zeer milde symptomen, en dus zullen veel mensen niet onopgemerkt blijven, vooral als de testcapaciteiten overbelast zijn en daarom beperkt blijven tot een kleine pool van mensen uit selecte groepen. De situatie in Washington, waar het virus al enkele weken voor het eerste bevestigde geval aanwezig bleek te zijn, onderstreept dit probleem goed.
Dus voordat we de gegevens gaan interpreteren (zo en zo is het sterftecijfer, en zo en zo is het aantal besmette patiënten), moeten we begrijpen hoe de gegevens zijn verzameld.
Een paar dagen geleden verscheen er een widget op mijn telefoonscherm met in rode letters het aantal bevestigde gevallen: 201463 mensen waren besmet met het coronavirus! Gezien het feit dat het werkelijke aantal wereldwijde gevallen er gemakkelijk een factor 10-50 naast kan zitten, denk ik niet dat het doen alsof je ze tot op de individuele persoon kunt tellen, bijdraagt aan een beter begrip van de moeilijkheid van het proces van gegevensverzameling.
Het sterftecijfer wordt ook vaak genoemd, maar er is een bijna even grote mate van onzekerheid aan verbonden: een enorme verstorende factor is demografie (tot 70% van de patiënten in Duitsland zijn jonge mensen in goede conditie die terugkeren van skitochten in Italië, wat een andere grote vertekening van de selectiegroep veroorzaakt), terwijl in Italië een groot deel van de getroffen mensen oud is, deels omdat oude mensen in Italië sterker geïntegreerd zijn in het sociale leven. En dan zijn er waarschijnlijk nog veel meer onopgemerkte gevallen in Italië (bedenk dat 70 Duitsers die terugkeerden van vakantie in Zuid-Tirol positief werden getest op een moment dat er in de hele deelstaat slechts 2 gevallen waren bevestigd). Dit, en het feit dat Duitsland meer en vroeger is gaan testen, heeft geleid tot een verschil in het sterftecijfer met een factor van bijna 50 tussen twee op het eerste gezicht relatief vergelijkbare landen.
Daarnaast moet rekening worden gehouden met het tijdsverloop tussen besmetting en herstel, de doeltreffendheid van de kritieke zorg, de rol van roken en luchtverontreiniging (hoog in Italië en China, en meer voorkomend bij mannen), de demografie van het land, de capaciteit van de ziekenhuizen, de vraag welke patiënten worden meegeteld als Covid-19 sterfgevallen (het eerste Duitse slachtoffer was een 78-jarige kankerpatiënt in een laat stadium die palliatieve zorg kreeg, dus men kan betwisten in welke mate zijn dood werkelijk moet worden meegerekend door Covid-19), enz.
Het is daarom misleidend om te zeggen “het sterftecijfer is dit en dat”, “en om te oordelen hoe gevaarlijk Covid-19 werkelijk is op basis van deze getallen alleen. Als we het hebben over een sterftecijfer, moeten we ons bewust zijn van waar het vandaan komt en wat het werkelijk zegt.
Opstellen van een Bayesiaans kader
In de Bayesiaanse statistiek drukken waarschijnlijkheden onze mate van geloof in een gebeurtenis uit. Een Bayesiaanse schatting van een grootheid omvat altijd wat we denken te weten over de grootheid, plus onze schatting van de inherente onzekerheid van de grootheid.
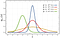
Nummers drukken onze kennis van deze wereld uit: maar omdat deze kennis noodzakelijkerwijs probabilistisch is, worden grootheden in de Bayesiaanse statistiek in plaats daarvan weergegeven door waarschijnlijkheidsverdelingen (die een belcurve kunnen zijn zoals in de bovenstaande grafiek) in plaats van losse getallen. De breedte van de verdeling vertegenwoordigt onze mate van zekerheid in onze schatting. Het hoogste punt van de grafiek is onze beste schatting (het gemiddelde van de Gaussian), maar als de verdeling erg breed is, zegt onze beste schatting ons niet al te veel.
Zoals deze grote diepgaande kijk op onze mogelijke maatregelen ertegen in detail uitlegt, zijn er heel veel onbekenden als het gaat om Covid-19, en te veel onbekenden om getallen met al te veel vertrouwen te hanteren (het verklaart ook waarom krachtige maatregelen op dit moment ons beste beleid zijn, omdat ze ons tijd geven om een duidelijker beeld te krijgen).

Deze grafiek is de wereld rondgereisd en komt uit een paper dat dit weekend is gepubliceerd door Neil Ferguson et al. aan het Imperial College London.
Ofschoon de boodschap ervan belangrijk is (zij heeft geleid tot beleidswijzigingen in de VS en het VK), is de manier waarop de grafiek de curven weergeeft misleidend. Wat zijn de impliciete parameters die in de simulatie zijn ingebracht, en hoe groot zijn hun betrouwbaarheidsintervallen? De effecten van het weer / verschillende sociale afstandsmaatregelen / sociale structuur / opkomende behandelingen zijn allemaal onzeker, en geen van deze factoren zijn vastgesteld door empirische studies, maar zijn, vooralsnog, gissingen.
Zoals Jeremy Howard zegt in zijn praktische samenvatting van de Covid-19 situatie, terwijl deze curven er gruwelijk uitzien, zouden de foutbalken eromheen bijna zo groot kunnen zijn als de curven zelf.
Onzekerheid weerstaan
Bottom line: het is misschien moeilijk om kalm te blijven in het aangezicht van onzekerheid, maar er schuilt enige wijsheid in.
Helaas wordt in politici het erkennen van onzekerheid vaak geïnterpreteerd als een teken van zwakte. Daarom denk ik dat het de verantwoordelijkheid van de wetenschappelijke gemeenschap is om te benadrukken welke rol zij speelt bij de evaluatie van wat er gebeurt, wat dit betekent met betrekking tot de maatregelen die we moeten nemen, en waarom deze onzekerheid een van de beste redenen is waarom we meer tijd nodig hebben om het virus langzaam te overwinnen door middel van een meer rigoureuze, wetenschappelijke evaluatie van het virus, en vervolgens te beslissen over de beste langetermijnstrategie.
We hebben graag cijfers om ons aan vast te houden wanneer de donkere wolk van de pandemie boven ons aller hoofd opdoemt. Maar voordat er duidelijkere feiten boven water komen, voordat de wereldgemeenschap meer grip op de situatie heeft, is het beter om de onzekerheid te weerstaan dan de feiten te bestendigen om ons zelfgenoegzaam te maken, of, het andere uiterste, onszelf in paniek te brengen door te denken dat we beter weten wat er aan de hand is dan we in werkelijkheid doen.