Klassificatie is een machine-leeraanpak onder supervisie, waarbij het algoritme leert van de gegevensinvoer die het krijgt – en dit leren vervolgens gebruikt om nieuwe waarnemingen te classificeren.
Met andere woorden, de trainingsdataset wordt gebruikt om betere randvoorwaarden te verkrijgen die kunnen worden gebruikt om elke doelklasse te bepalen; zodra die randvoorwaarden zijn bepaald, is de volgende taak het voorspellen van de doelklasse.
Binaire classifiers werken met slechts twee klassen of mogelijke uitkomsten (bijvoorbeeld: positief of negatief sentiment; of de kredietgever de lening zal betalen of niet; enz.), en multiklass classifiers werken met meerdere klassen (bijvoorbeeld: tot welk land een vlag behoort, of een afbeelding een appel, banaan of sinaasappel is; enz.) Bij multiklassen wordt ervan uitgegaan dat aan elk monster slechts één label wordt toegekend.

Eén van de eerste populaire algoritmen voor classificatie bij machinaal leren was Naive Bayes, een probabilistische classificator die is geïnspireerd op het theorema van Bayes (dat ons in staat stelt beredeneerde deducties te maken van gebeurtenissen die in de echte wereld plaatsvinden op basis van voorafgaande kennis van waarnemingen die dit kunnen impliceren). De naam (“Naïef”) is afgeleid van het feit dat het algoritme ervan uitgaat dat attributen voorwaardelijk onafhankelijk zijn.
Het algoritme is eenvoudig te implementeren en vormt gewoonlijk een redelijke methode om een begin te maken met classificatie-inspanningen. Het kan gemakkelijk worden opgeschaald naar grotere datasets (neemt lineaire tijd versus iteratieve benadering, zoals gebruikt voor veel andere soorten classifiers, die duurder is in termen van rekenkracht) en vereist een kleine hoeveelheid trainingsgegevens.
Naive Bayes kan echter last hebben van een probleem dat bekend staat als ‘nulwaarschijnlijkheidsprobleem’, wanneer de voorwaardelijke waarschijnlijkheid nul is voor een bepaald attribuut, waardoor het geen geldige voorspelling kan doen. Een oplossing hiervoor is het gebruik van een afvlakkingsprocedure (bijv. Laplace-methode).

P(c|x) is de posterieure waarschijnlijkheid van klasse (c, doel) gegeven voorspeller (x, attributen). P(c) is de prioritaire waarschijnlijkheid van de klasse. P(x|c) is de waarschijnlijkheid die de waarschijnlijkheid is van de voorspeller gegeven de klasse, en P(x) is de voorafgaande waarschijnlijkheid van de voorspeller.
De eerste stap van het algoritme is het berekenen van de voorafgaande waarschijnlijkheid voor gegeven klasse-etiketten. Vervolgens wordt de waarschijnlijkheid met elk attribuut, voor elke klasse, gevonden. Vervolgens worden deze waarden in de Bayes-formule & gebracht om de posterior waarschijnlijkheid te berekenen, en vervolgens te zien welke klasse een hogere waarschijnlijkheid heeft, gegeven het feit dat de invoer tot de klasse met de hogere waarschijnlijkheid behoort.
Het is vrij eenvoudig om Naive Bayes in Python te implementeren door gebruik te maken van de scikit-learn bibliotheek. Er zijn eigenlijk drie soorten Naive Bayes model onder de scikit-learn bibliotheek: (a) Gaussian type (veronderstelt dat kenmerken een klok-achtige, normale verdeling volgen), (b) Multinomial (gebruikt voor discrete tellingen, in termen van het aantal keren dat een uitkomst is waargenomen over x proeven), en (c) Bernoulli (nuttig voor binaire kenmerkvectoren; populaire use-case is tekstclassificatie).
Een ander populair mechanisme is de Beslisboom. Gegeven een gegeven van attributen samen met zijn klassen, produceert de boom een opeenvolging van regels die kunnen worden gebruikt om de gegevens te classificeren. Het algoritme verdeelt de steekproef in twee of meer homogene reeksen (bladeren) op basis van de belangrijkste differentiatoren in uw invoervariabelen. Om een differentiator (voorspeller) te kiezen, beschouwt het algoritme alle kenmerken en voert het een binaire splitsing op hen uit (voor categorische gegevens, splitsing per kat; voor continue, kies een afkapdrempel). Het algoritme kiest dan het kenmerk met de laagste kosten (d.w.z. de hoogste nauwkeurigheid), en herhaalt dit recursief, totdat het erin geslaagd is de gegevens in alle bladeren te splitsen (of de maximale diepte heeft bereikt).
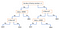
Decision Trees zijn over het algemeen eenvoudig te begrijpen en te visualiseren, en vereisen weinig voorbereiding van de gegevens. Deze methode kan ook overweg met zowel numerieke als categorische gegevens. Aan de andere kant generaliseren complexe bomen niet goed (“overfitting”), en kunnen beslisbomen enigszins instabiel zijn omdat kleine variaties in de gegevens ertoe kunnen leiden dat een geheel andere boom wordt gegenereerd.
Een classificatiemethode die is afgeleid van beslisbomen is Random Forest, in wezen een “meta-estimator” die een aantal beslisbomen toepast op verschillende deelsteekproeven van datasets en het gemiddelde gebruikt om de voorspellende nauwkeurigheid van het model te verbeteren en over-fitting tegen te gaan. De grootte van de substeekproef is gelijk aan die van de oorspronkelijke inputsteekproef, maar de steekproeven worden getrokken met vervanging.
Random Forests zijn meestal beter bestand tegen overfitting (>robuustheid voor ruis in de gegevens), met een efficiënte uitvoeringstijd, zelfs bij grotere datasets. Zij zijn echter gevoeliger voor onevenwichtige datasets, maar zijn ook iets ingewikkelder te interpreteren en vereisen meer rekenkracht.
Een andere populaire classifier in ML is Logistische Regressie – waarbij de waarschijnlijkheden die de mogelijke uitkomsten van een enkele proef beschrijven, worden gemodelleerd met behulp van een logistische functie (classificatiemethode ondanks de naam):

Hier ziet de logistische vergelijking er als volgt uit:
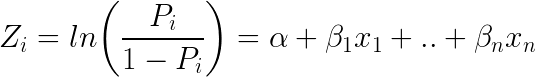
Het nemen van e (exponent) aan beide zijden van de vergelijking resulteert in:
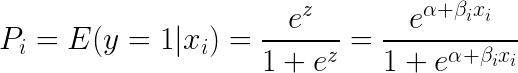
Logistische regressie is het nuttigst om de invloed van verschillende onafhankelijke variabelen op een enkele uitkomstvariabele te begrijpen. Zij is gericht op binaire classificatie (voor problemen met meerdere klassen gebruiken we uitbreidingen van logistische regressie, zoals multinomiale en ordinale logistische regressie). Logistische regressie is populair in gebruikscases zoals kredietanalyse en neiging tot reageren/kopen.
Last but not least, kNN (voor “k Nearest Neighbors”) wordt ook vaak gebruikt voor classificatieproblemen. kNN is een eenvoudig algoritme dat alle beschikbare gevallen opslaat en nieuwe gevallen classificeert op basis van een gelijksoortigheidsmaat (b.v. afstandsfuncties). Het is al in het begin van de jaren zeventig in statistische schattingen en patroonherkenning gebruikt als een niet-parametrische techniek:

