Les structures de données arborescentes ont de nombreuses utilisations, et il est bon d’avoir une compréhension de base de leur fonctionnement. Les arbres sont la base d’autres structures de données très utilisées comme les Maps et les Sets. Ils sont également utilisés dans les bases de données pour effectuer des recherches rapides. Le HTML DOM utilise une structure de données arborescente pour représenter la hiérarchie des éléments. Ce post explorera les différents types d’arbres comme les arbres binaires, les arbres de recherche binaire, et comment les implémenter.
Nous avons exploré les structures de données Graph dans le post précédent, qui sont un cas généralisé d’arbres. Commençons à apprendre ce que sont les structures de données d’arbres !
Ce post fait partie d’une série de tutoriels :
Apprendre les structures de données et les algorithmes (DSA) pour les débutants
-
Intro à la complexité temporelle des algorithmes et à la notation Big O
-
Huit complexités temporelles que tout programmeur devrait connaître
-
Structures de données pour les débutants : Tableaux, hachages et listes
-
Structures de données graphiques pour débutants
-
Arbres Structures de données pour débutants 👈 you are here
-
Arbres de recherche binaire auto-équilibrés
-
Appendice I : Analyse des algorithmes récursifs
Arbres : concepts de base
Un arbre est une structure de données où un nœud peut avoir zéro ou plusieurs enfants. Chaque nœud contient une valeur. Comme les graphes, la connexion entre les nœuds est appelée arêtes. Un arbre est un type de graphe, mais tous les graphes ne sont pas des arbres (nous y reviendrons plus tard).
Ces structures de données sont appelées « arbres » parce que la structure de données ressemble à un arbre 🌳. Elle commence par un nœud racine et se ramifie avec ses descendants, et enfin, il y a des feuilles.
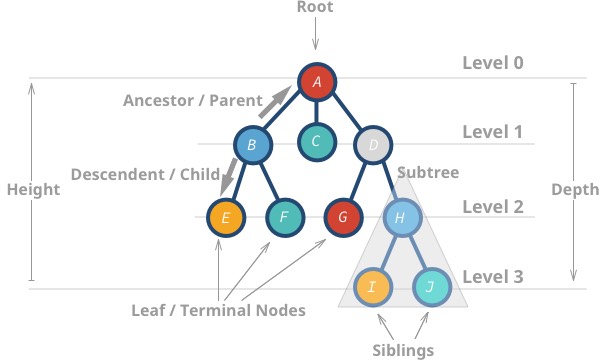
Voici quelques propriétés des arbres :
- Le nœud le plus haut est appelé racine.
- Un nœud sans enfants est appelé nœud feuille ou nœud terminal.
- La hauteur (h) de l’arbre est la distance (nombre d’arêtes) entre la feuille la plus éloignée et la racine.
-
Aa une hauteur de 3 -
Ia une hauteur de 0
-
- La profondeur ou le niveau d’un nœud est la distance entre la racine et le nœud en question.
-
Ha une profondeur de 2 -
Ba une profondeur de 1
-
Mise en œuvre d’une structure de données arborescente simple
Comme nous l’avons vu précédemment, un nœud d’arbre est juste une structure de données avec une valeur et des liens vers ses descendants.
Voici un exemple de nœud d’arbre :
1 |
class TreeNode {
|
Nous pouvons créer un arbre avec 3 descendants comme suit :
1 |
// create nodes with values |
C’est tout ; nous avons une structure de données arborescente !
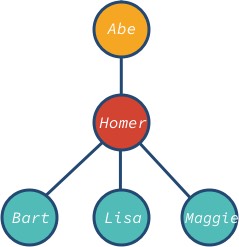
Le nœud abe est la racine et bart, lisa et maggie sont les nœuds feuilles de l’arbre. Remarquez que le nœud de l’arbre peut avoir différents descendants : 0, 1, 3, ou toute autre valeur.
Les structures de données arborescentes ont de nombreuses applications telles que :
- Cartes
- Ensembles
- Bases de données
- Files d’attente prioritaires
- Interroger un LDAP (Lightweight Directory Access Protocol)
- Représenter le modèle d’objet de document (DOM) pour le HTML sur les sites Web.
Arbres binaires
Les nœuds des arbres peuvent avoir zéro ou plusieurs enfants. Cependant, lorsqu’un arbre a au plus deux enfants, on parle alors d’arbre binaire.
Arbres binaires pleins, complets et parfaits
Selon la façon dont les nœuds sont disposés dans un arbre binaire, celui-ci peut être plein, complet et parfait :
- Arbre binaire plein : chaque nœud a exactement 0 ou 2 enfants (mais jamais 1).
- Arbre binaire complet : lorsque tous les niveaux, sauf le dernier, sont pleins de nœuds.
- Arbre binaire parfait : lorsque tous les niveaux (y compris le dernier) sont pleins de nœuds.
Regardez ces exemples :
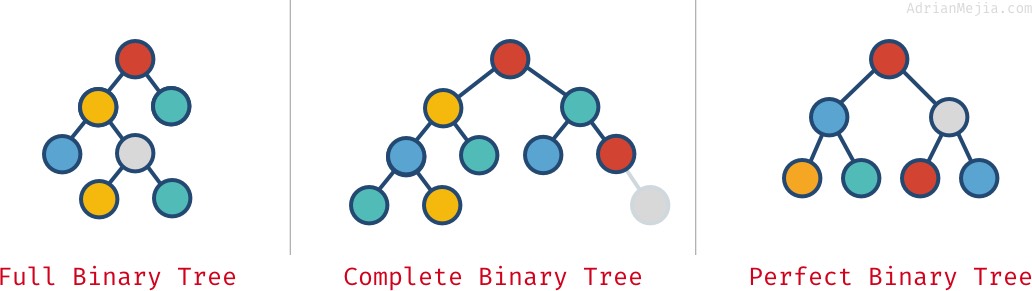
Ces propriétés ne sont pas toujours mutuellement exclusives. Vous pouvez en avoir plusieurs:
- Un arbre parfait est toujours complet et plein.
- Les arbres binaires parfaits ont précisément `2^k – 1` nœuds, où
kest le dernier niveau de l’arbre (en commençant par 1).
- Les arbres binaires parfaits ont précisément `2^k – 1` nœuds, où
- Un arbre complet n’est pas toujours
full.- Comme dans notre exemple « complet », puisqu’il a un parent avec un seul enfant. Si nous enlevons le nœud gris le plus à droite, alors nous aurions un arbre complet et plein mais pas parfait.
- Un arbre complet n’est pas toujours complet et parfait.
Arbre de recherche binaire (BST)
Les arbres de recherche binaire ou BST pour faire court sont une application particulière des arbres binaires. BST a au plus deux nœuds (comme tous les arbres binaires). Cependant, les valeurs sont telles que la valeur des enfants de gauche doit être inférieure à celle du parent, et celle des enfants de droite doit être supérieure.
Doubles : Certains BST ne permettent pas les doublons tandis que d’autres ajoutent les mêmes valeurs en tant qu’enfant de droite. D’autres implémentations pourraient garder un compte sur un cas de duplicité (nous allons faire celui-ci plus tard).
Implémentons un arbre de recherche binaire!
Implémentation BST
Les BST sont très similaires à notre précédente implémentation d’un arbre. Cependant, il y a quelques différences:
- Les nœuds peuvent avoir, au maximum, seulement deux enfants : gauche et droite.
- Les valeurs des nœuds doivent être ordonnées comme
left < parent < right.
Voici le nœud de l’arbre. Très similaire à ce que nous avons fait avant, mais nous avons ajouté quelques getters et setters pratiques pour les enfants de gauche et de droite. Remarquez que garde également une référence au parent, et nous la mettons à jour chaque fois que nous ajoutons des enfants.
1 |
const LEFT = 0; |
Ok, jusqu’ici, nous pouvons ajouter un enfant gauche et droit. Maintenant, faisons la classe BST qui applique la règle left < parent < right.
1 |
|
Implémentons l’insertion.
Insertion de nœud BST
Pour insérer un nœud dans un arbre binaire, nous faisons ce qui suit :
- Si un arbre est vide, le premier nœud devient la racine, et vous avez terminé.
- Comparer la valeur de la racine/du parent si elle est supérieure allez à droite, si elle est inférieure allez à gauche. Si c’est la même chose, alors la valeur existe déjà, de sorte que vous pouvez augmenter le nombre de doublons (multiplicité).
- Répétez #2 jusqu’à ce que nous ayons trouvé un emplacement vide pour insérer le nouveau nœud.
Faisons une illustration comment insérer 30, 40, 10, 15, 12, 50:
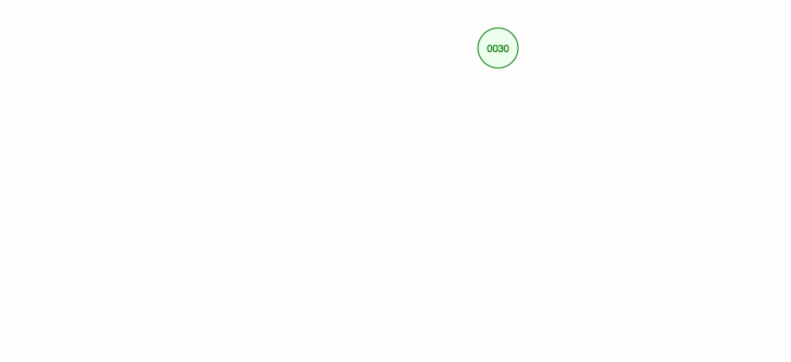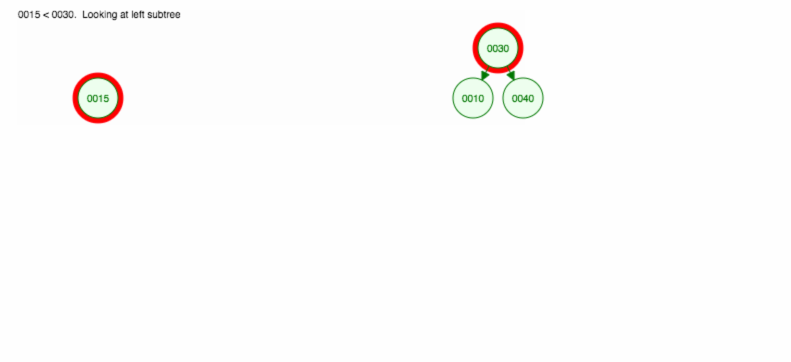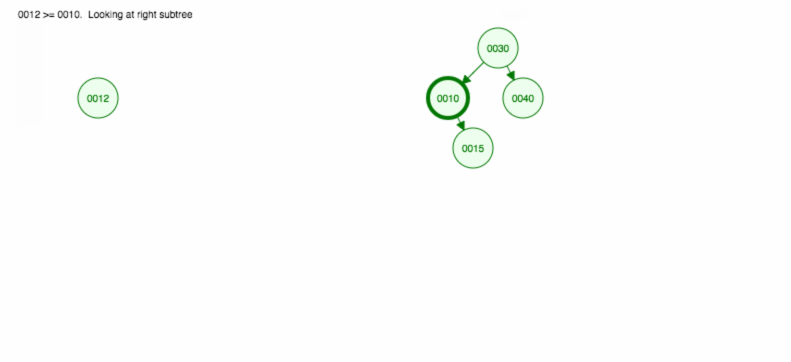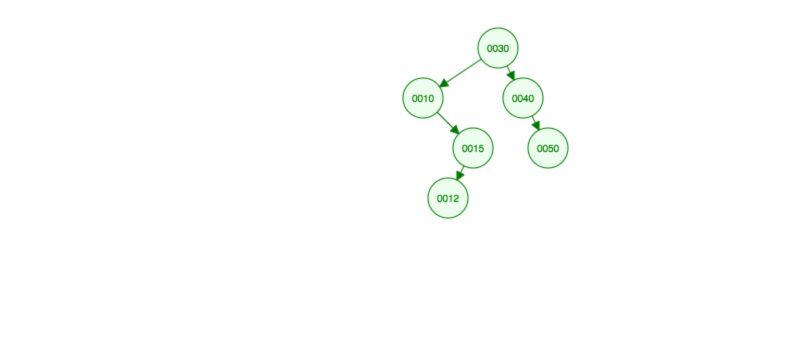
Nous pouvons implémenter l’insertion comme suit:
1 |
add(value) {
|
Nous utilisons une fonction d’aide appelée findNodeAndParent. Si nous avons trouvé que le nœud existe déjà dans l’arbre, alors nous augmentons le compteur multiplicity. Voyons comment cette fonction est implémentée:
1 |
findNodeAndParent(value) {
|
findNodeAndParent parcourt l’arbre, à la recherche de la valeur. Il commence à la racine (ligne 2) et va ensuite à gauche ou à droite en fonction de la valeur (ligne 10). Si la valeur existe déjà, elle renvoie le nœud found et aussi le parent. Dans le cas où le nœud n’existe pas, on retourne quand même le parent.
Suppression de nœud BST
Nous savons comment insérer et rechercher une valeur. Maintenant, nous allons mettre en œuvre l’opération de suppression. C’est un peu plus délicat que l’ajout, alors expliquons-le avec les cas suivants :
Suppression d’un nœud feuille (0 enfant)
1 |
30 30 |
Nous supprimons la référence du parent (15) du nœud pour qu’il soit nul.
Suppression d’un nœud avec un enfant.
1 |
30 30 |
Dans ce cas, nous allons au parent (30) et remplaçons l’enfant (10) par l’enfant d’un enfant (15).
Suppression d’un nœud avec deux enfants
1 |
30 30 |
Nous supprimons le nœud 40, qui a deux enfants (35 et 50). Nous remplaçons l’enfant (40) du parent (30) par l’enfant de droite (50). Ensuite, nous gardons l’enfant gauche (35) au même endroit avant, donc nous devons en faire l’enfant gauche de 50.
Une autre façon de supprimer le nœud 40 est de déplacer l’enfant gauche (35) vers le haut et ensuite de garder l’enfant droit (50) là où il était.
1 |
30 |
L’une ou l’autre façon est ok tant que vous gardez la propriété d’arbre de recherche binaire : left < parent < right.
Suppression de la racine.
1 |
30* 50 |
Supprimer la racine est très similaire à la suppression des nœuds avec 0, 1 ou 2 enfants discutée précédemment. La seule différence est qu’après, nous devons mettre à jour la référence de la racine de l’arbre.
Voici une animation de ce dont nous avons discuté.
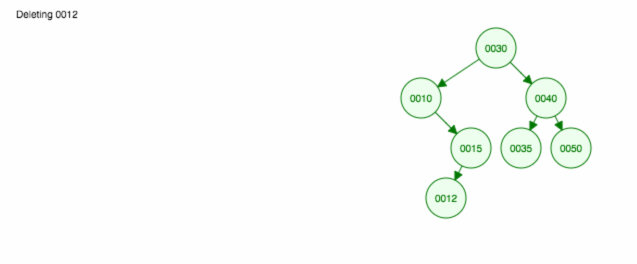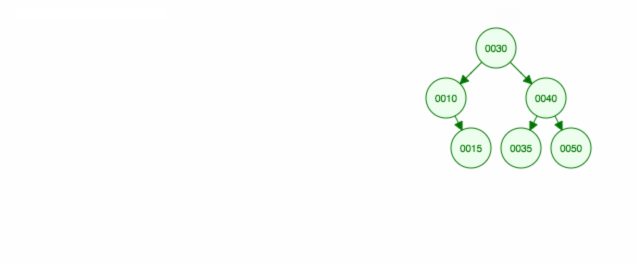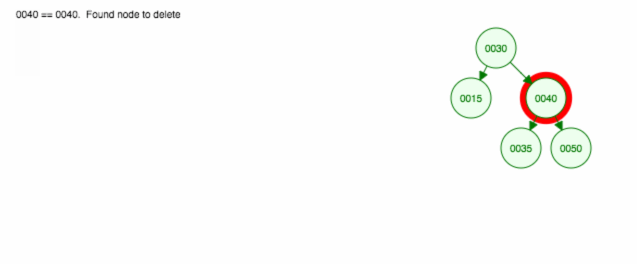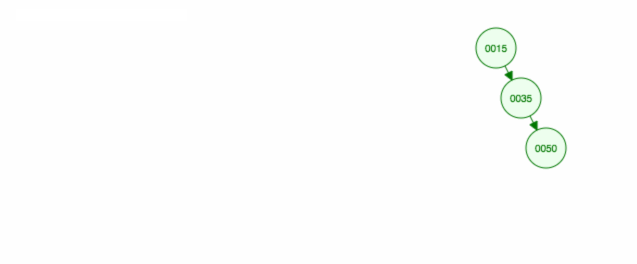
L’animation remonte l’enfant/sous-arbre gauche et maintient l’enfant/sous-arbre droit en place.
Maintenant que nous avons une bonne idée de comment cela devrait fonctionner, implémentons-le:
1 |
remove(value) {
|
Voici quelques points saillants de l’implémentation:
- D’abord, nous cherchons si le nœud existe. S’il n’existe pas, nous retournons false, et nous avons terminé!
- Si le nœud à supprimer existe, alors on combine les enfants de gauche et de droite en un seul sous-arbre.
- Remplacer le nœud à supprimer avec le sous-arbre combiné.
La fonction qui combine le sous-arbre de gauche en sous-arbre de droite est la suivante:
1 |
combineLeftIntoRightSubtree(node) {
|
Par exemple, disons que nous voulons combiner l’arbre suivant, et que nous sommes sur le point de supprimer le nœud 30. Nous voulons mélanger le sous-arbre de gauche du 30 dans celui de droite. Le résultat est le suivant :
1 |
30* 40 |
Si nous faisons du nouveau sous-arbre la racine, alors le nœud 30 n’est plus !
Traversée d’un arbre binaire
Il existe différentes façons de traverser un arbre binaire, selon l’ordre dans lequel les nœuds sont visités : in-order, pre-order et post-order. De plus, nous pouvons les utiliserDFSetBFSque nous avons appris dans le postgraph.Passons en revue chacune d’entre elles.
Traversée en ordre
La traversée en ordre visite les nœuds dans cet ordre : gauche, parent, droite.
1 |
* inOrderTraversal(node = this.root) {
|
Utilisons cet arbre pour faire l’exemple :
1 |
10 |
Une traversée en ordre imprimerait les valeurs suivantes : 3, 4, 5, 10, 15, 30, 40. Si l’arbre est un BST, alors les nœuds seront triés par ordre ascendant comme dans notre exemple.
Post-Order Traversal
Post-order traversal visitent les nœuds sur cet ordre : gauche, droite, parent.
1 |
* postOrderTraversal(node = this.root) {
|
La traversée post-ordre imprimerait les valeurs suivantes : 3, 4, 5, 15, 40, 30, 10.
Traversée préordonnée et DFS
La traversée préordonnée visite les nœuds sur cet ordre : parent, gauche, droite.
1 |
* preOrderTraversal(node = this.root) {
|
La traversée préordonnée imprimerait les valeurs suivantes : 10, 5, 4, 3, 30, 15, 40. Cet ordre des nombres est le même résultat que celui que nous obtiendrions si nous exécutions la recherche en profondeur avant tout (DFS).
1 |
* dfs() {
|
Si vous avez besoin d’un rafraîchissement sur la DFS, nous l’avons couverte en détail sur le post Graph.
Recherche en premier de la largeur (BFS)
Similaire à DFS, nous pouvons mettre en œuvre un BFS en changeant le Stack par un Queue:
1 |
* bfs() {
|
L’ordre du BFS est : 10, 5, 30, 4, 15, 40, 3
Arbres équilibrés contre arbres non équilibrés
Jusqu’à présent, nous avons discuté de la façon de add, remove, et find éléments. Cependant, nous n’avons pas parlé des temps d’exécution. Réfléchissons aux pires scénarios.
Disons que nous voulons ajouter des nombres dans l’ordre croissant.
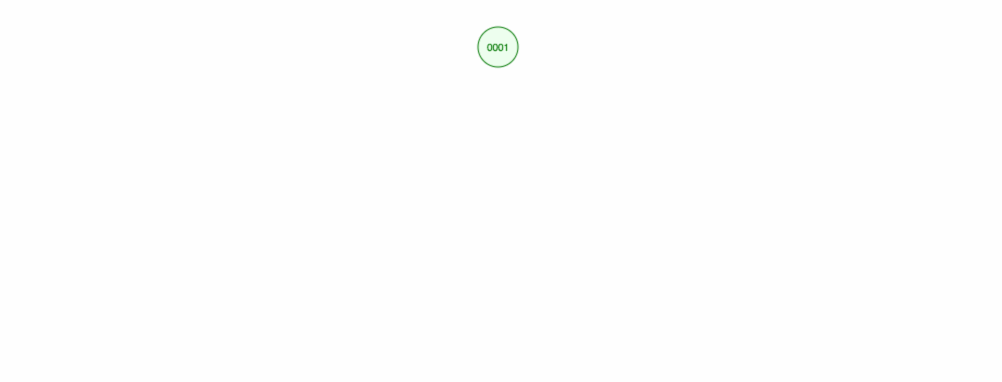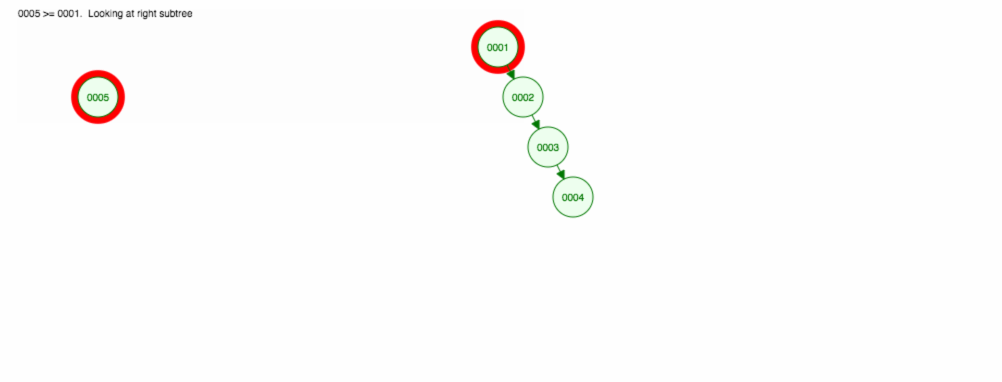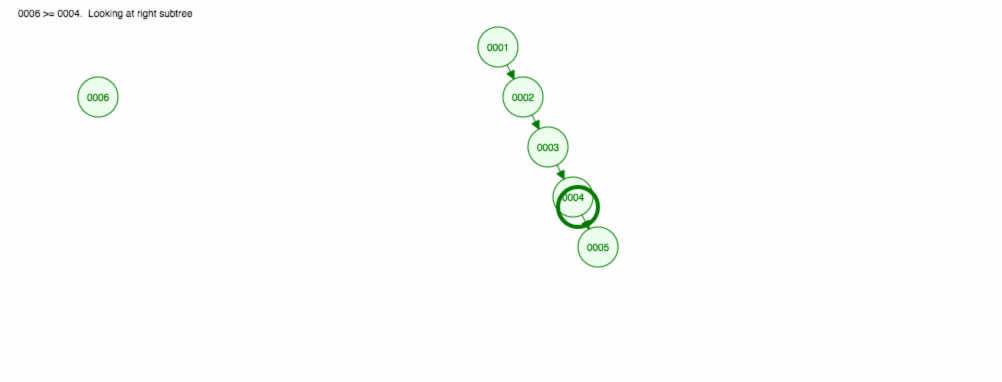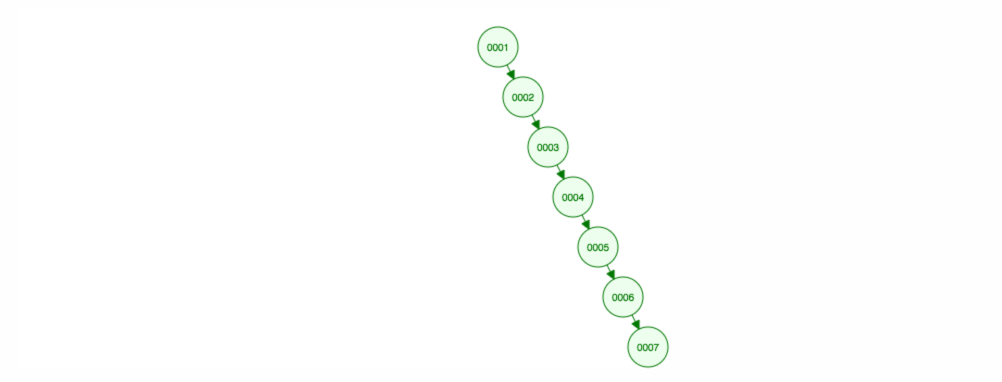
Nous nous retrouverons avec tous les nœuds du côté droit ! Cet arbre déséquilibré n’est pas mieux qu’une LinkedList, donc trouver un élément prendrait O(n). 😱
Rechercher quelque chose dans un arbre non équilibré, c’est comme chercher un mot dans le dictionnaire page par page. Lorsque l’arbre est équilibré, vous pouvez ouvrir le dictionnaire au milieu, et à partir de là, vous savez si vous devez aller à gauche ou à droite selon l’alphabet et le mot que vous cherchez.
Nous devons trouver un moyen d’équilibrer l’arbre !
Si l’arbre était équilibré, nous pourrions trouver des éléments en O(log n) au lieu de passer par chaque nœud. Parlons de ce que signifie un arbre équilibré.
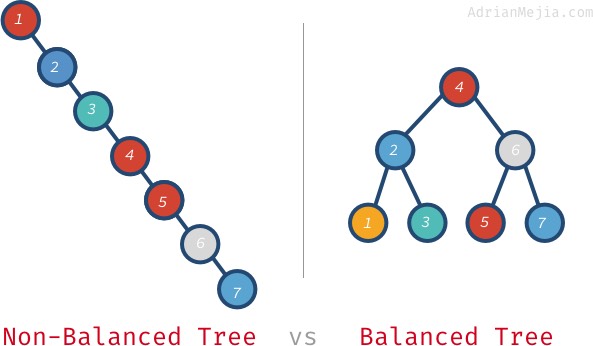
Si nous cherchons 7 dans l’arbre non équilibré, nous devons aller de 1 à 7. Cependant, dans l’arbre équilibré, nous visitons : 4, 6, et 7. C’est encore pire avec des arbres plus grands. Si vous avez un million de nœuds, la recherche d’un élément inexistant pourrait vous obliger à visiter tout le million alors que sur un arbre équilibré. Il suffit de 20 visites ! C’est une énorme différence !
Nous allons résoudre ce problème dans le prochain post en utilisant des arbres auto-équilibrés (arbres AVL).
Résumé
Nous avons couvert beaucoup de terrain pour les arbres. Résumons le tout avec des puces:
- L’arbre est une structure de données où un nœud a 0 ou plusieurs descendants/enfants.
- Les nœuds de l’arbre n’ont pas de cycles (acyclique). S’il a des cycles, c’est une structure de données Graph à la place.
- Les arbres avec deux enfants ou moins sont appelés : Arbre binaire
- Lorsqu’un arbre binaire est trié de façon à ce que la valeur de gauche soit inférieure au parent et que les enfants de droite soient supérieurs, alors et seulement alors nous avons un arbre de recherche binaire.
- Vous pouvez visiter un arbre de façon pré/post/en ordre.
- Un déséquilibre a une complexité temporelle de O(n). 🤦🏻
- Un équilibré a une complexité temporelle de O(log n). 🎉